import os
import pickle
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras import Model, layers
data_path = "../data/mixedtype-wafer-defect-datasets/Wafer_Map_Datasets.npz"
data = np.load(data_path)
images = data["arr_0"]
labels = data["arr_1"]Mixed-type Wafer Map Defect Dataset
- [‘arr_0’]: Defect data of mixed-type wafer map, 0 means blank spot, 1 represents normal die that passed the electrical test, and 2 represents broken die that failed the electrical test. The data shape is 52×52.
- [‘arr_1’]: Mixed-type wafer map defect label, using one-hot encoding, a total of 8 dimensions, corresponding to the 8 basic types of wafer map defects (single defect).
Data Exploration
Labels
# Basic summary of labels
print("Labels shape:", labels.shape)
print("Total entries:", labels.shape[0])
# Unique values across entire labels array
unique_vals = np.unique(labels)
print("Unique values:", unique_vals)
print("Number of unique values:", unique_vals.size)
# Missing data check
missing_count = np.isnan(labels).sum()
print("Missing values (NaN) count:", missing_count)
# Show a few example label rows
examples_df = pd.DataFrame(labels[:5])
print("Example label rows:")
display(examples_df)
# Unique row patterns count
unique_rows = np.unique(labels, axis=0)
print("Number of unique label patterns:", unique_rows.shape[0])Labels shape: (38015, 8)
Total entries: 38015
Unique values: [0 1]
Number of unique values: 2
Missing values (NaN) count: 0
Example label rows:| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 3 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
Number of unique label patterns: 38label_mapping = {
"00000000": "Normal",
"10000000": "Center",
"01000000": "Donut",
"00100000": "Edge_Loc",
"00010000": "Edge_Ring",
"00001000": "Loc",
"00000100": "Near_Full",
"00000010": "Scratch",
"00000001": "Random",
"10100000": "Center+Edge_Loc",
"10010000": "Center+Edge_Ring",
"10001000": "Center+Loc",
"10000010": "Center+Scratch",
"01100000": "Donut+Edge_Loc",
"01010000": "Donut+Edge_Ring",
"01001000": "Donut+Loc",
"01000010": "Donut+Scratch",
"00101000": "Edge_Loc+Loc",
"00100010": "Edge_Loc+Scratch",
"00011000": "Edge_Ring+Loc",
"00010010": "Edge_Ring+Scratch",
"00001010": "Loc+Scratch",
"10101000": "Center+Edge_Loc+Loc",
"10100010": "Center+Edge_Loc+Scratch",
"10011000": "Center+Edge_Ring+Loc",
"10010010": "Center+Edge_Ring+Scratch",
"10001010": "Center+Loc+Scratch",
"01101000": "Donut+Edge_Loc+Loc",
"01100010": "Donut+Edge_Loc+Scratch",
"01011000": "Donut+Edge_Ring+Loc",
"01010010": "Donut+Edge_Ring+Scratch",
"01001010": "Donut+Loc+Scratch",
"00101010": "Edge_Loc+Loc+Scratch",
"00011010": "Edge_Ring+Loc+Scratch",
"10101010": "Center+Edge_Loc+Loc+Scratch",
"10011010": "Center+Edge_Ring+Loc+Scratch",
"01101010": "Donut+Edge_Loc+Loc+Scratch",
"01011010": "Donut+Edge_Ring+Loc+Scratch",
}
# Convert one-hot vectors to string keys
label_str = ["".join(map(str, map(int, row))) for row in labels]
label_names = [label_mapping.get(key, "Unknown") for key in label_str]
# Count frequency
label_counts = Counter(label_str)
# Create DataFrame with label names
label_df = (
pd
.DataFrame([
{"OneHot": k, "Count": v, "LabelName": label_mapping.get(k, "Unknown")} for k, v in label_counts.items()
])
.sort_values("OneHot")
.reset_index(drop=True)
)
# plot label distribution with seaborn
sns.set_theme(style="whitegrid")
plt.figure(figsize=(12, 7))
sns.barplot(data=label_df, x="Count", y="LabelName", order=label_df.sort_values("Count", ascending=False)["LabelName"])
plt.xlabel("Frequency")
plt.ylabel("Defect Type")
plt.title("Distribution of Wafer Defect Types")
plt.tight_layout()
plt.show()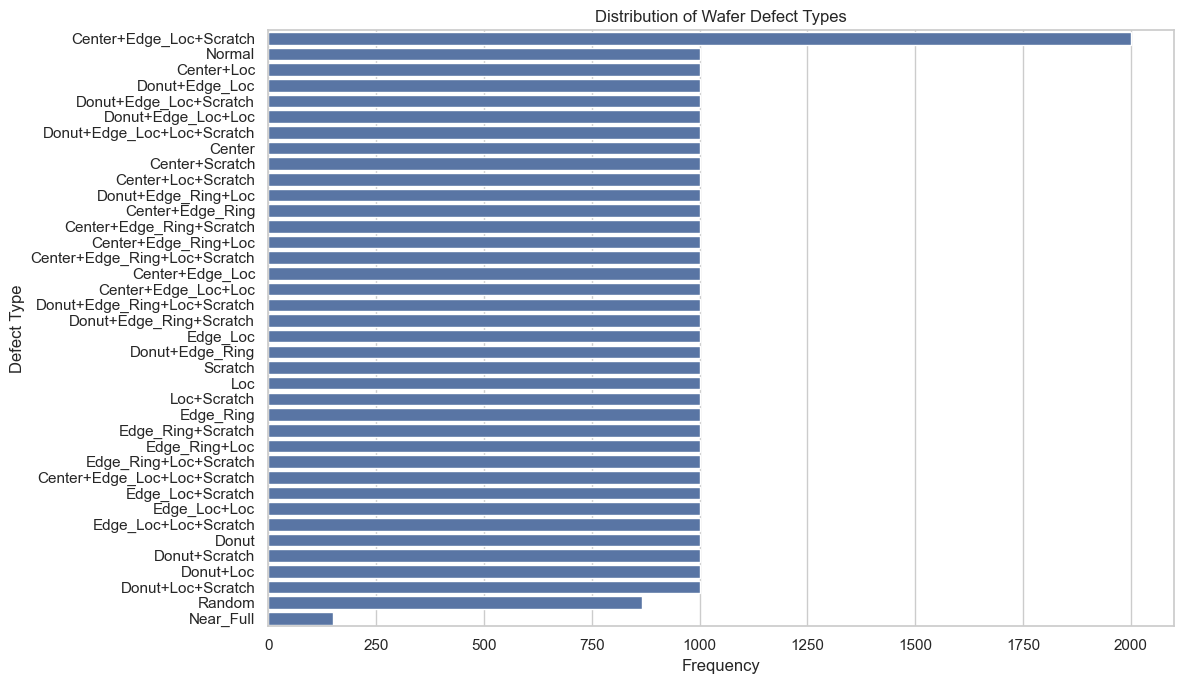
From the plot above, we can see that for most of the defect labels we have 1,000 images including the normal wafers. But for Center+Edge_loc+Scratch we have 2,000 images, for Random around 800 and for Near_Full an under representation of ~200 images.
Images
# Basic summary of images array
print("Images shape:", images.shape)
print("Total entries:", images.shape[0])
print("Single image shape:", images[0].shape)
print("Dtype:", images.dtype)
# Missing data check
missing_count_images = np.isnan(images).sum()
print("Missing values (NaN) count:", missing_count_images)
# Unique values across entire images array
unique_vals_images = np.unique(images)
print("Unique values:", unique_vals_images)
print("Number of unique values:", unique_vals_images.size)
# Count images with at least one pixel value of 3
images_with_3 = np.sum(np.any(images == 3, axis=(1, 2)))
print(f"Images with at least one pixel value of 3: {images_with_3}")
# in the images that have at least one pixel value of 3, tell me the average of many pixels have the value 3
images_with_3_pixels = images[np.any(images == 3, axis=(1, 2))]
count_3_pixels = np.sum(images_with_3_pixels == 3)
average_3_pixels = count_3_pixels / images_with_3
print(f"Average number of pixels with value 3 in those images: {average_3_pixels}")
# Show a few example images (as arrays)
sample_images = images[:3]
print("Sample image arrays:")
for i, img in enumerate(sample_images, start=1):
print(f"Image {i} shape: {img.shape}")
print(img)Images shape: (38015, 52, 52)
Total entries: 38015
Single image shape: (52, 52)
Dtype: int32
Missing values (NaN) count: 0
Unique values: [0 1 2 3]
Number of unique values: 4
Images with at least one pixel value of 3: 105
Average number of pixels with value 3 in those images: 2.038095238095238
Sample image arrays:
Image 1 shape: (52, 52)
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
Image 2 shape: (52, 52)
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
Image 3 shape: (52, 52)
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]# make pixels with value 3 be 0
images[images == 3] = 0def convert_to_rgb(image):
height, width = image.shape
rgb_image = np.zeros((height, width, 3), dtype=np.uint8)
rgb_image[image == 0] = [0, 63, 92]
rgb_image[image == 1] = [255, 166, 0]
rgb_image[image == 2] = [188, 80, 144]
return rgb_image
# Separate labels by number of defects (number of '+' in label name)
unique_labels = label_df["LabelName"].tolist()
labels_by_defect_count = {0: [], 1: [], 2: [], 3: []}
for label_name in unique_labels:
plus_count = label_name.count("+")
labels_by_defect_count[plus_count].append(label_name)
# Plot each group separately
sns.set_theme(style="white")
for defect_count, labels_group in labels_by_defect_count.items():
if not labels_group:
continue
n_labels = len(labels_group)
n_cols = min(5, n_labels)
n_rows = (n_labels + n_cols - 1) // n_cols
fig, axes = plt.subplots(n_rows, n_cols, figsize=(16, n_rows * 3))
axes = [axes] if n_labels == 1 else axes.flatten() if n_rows > 1 else axes
for idx, label_name in enumerate(labels_group):
label_idx = label_names.index(label_name)
rgb_image = convert_to_rgb(images[label_idx])
axes[idx].imshow(rgb_image)
axes[idx].set_title(label_name, fontsize=10, fontweight="bold", color="#333333")
axes[idx].axis("off")
axes[idx].spines["top"].set_visible(False)
axes[idx].spines["right"].set_visible(False)
axes[idx].spines["bottom"].set_visible(False)
axes[idx].spines["left"].set_visible(False)
# Hide unused subplots
for idx in range(n_labels, len(axes)):
axes[idx].axis("off")
fig.patch.set_facecolor("white")
plt.axis("off")
plt.tight_layout()
# Add a suptitle for the group
if defect_count == 0:
fig.suptitle("Single Defect Types", fontsize=16, fontweight="bold", y=1.02)
else:
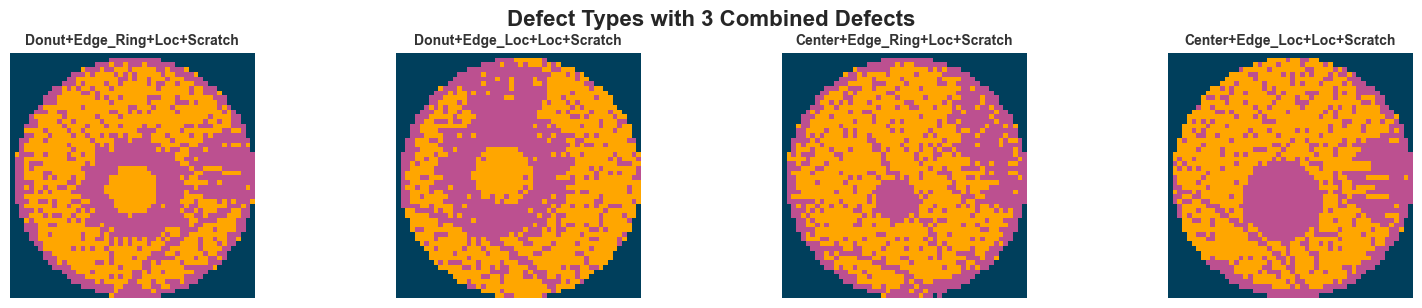
fig.suptitle(f"Defect Types with {defect_count} Combined Defects", fontsize=16, fontweight="bold", y=1.02)
plt.show()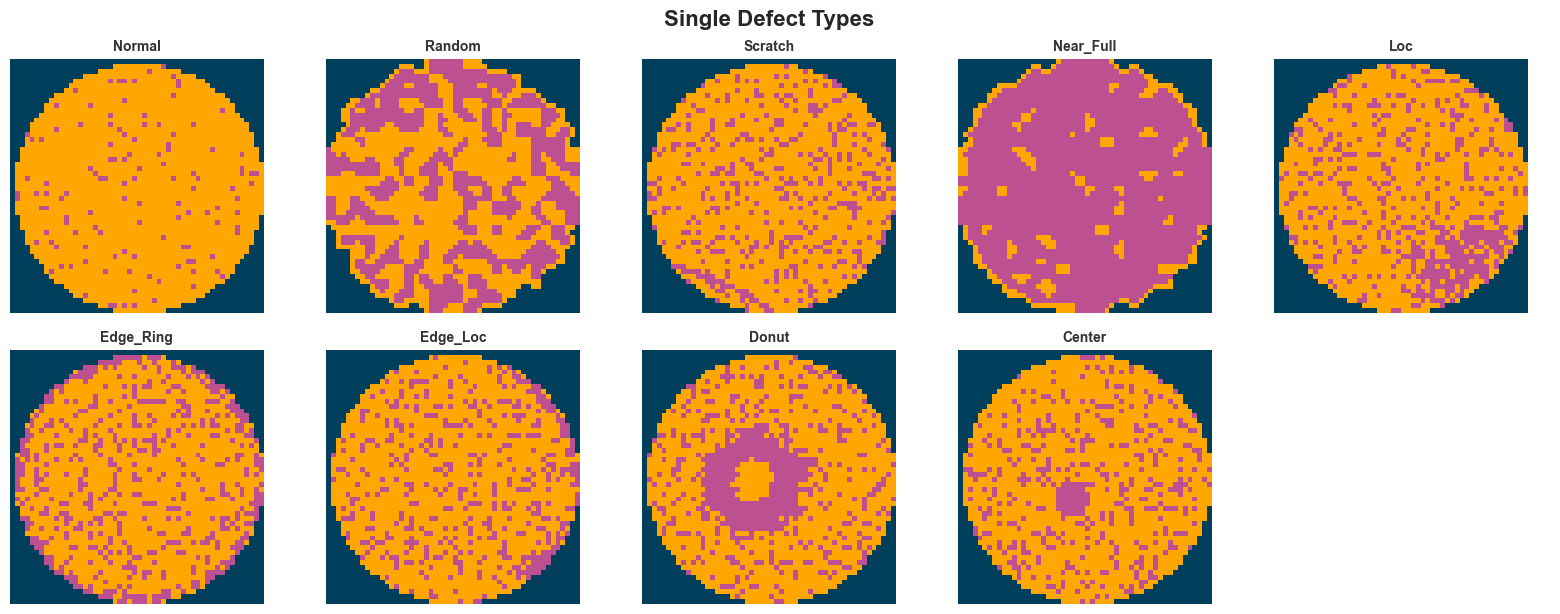
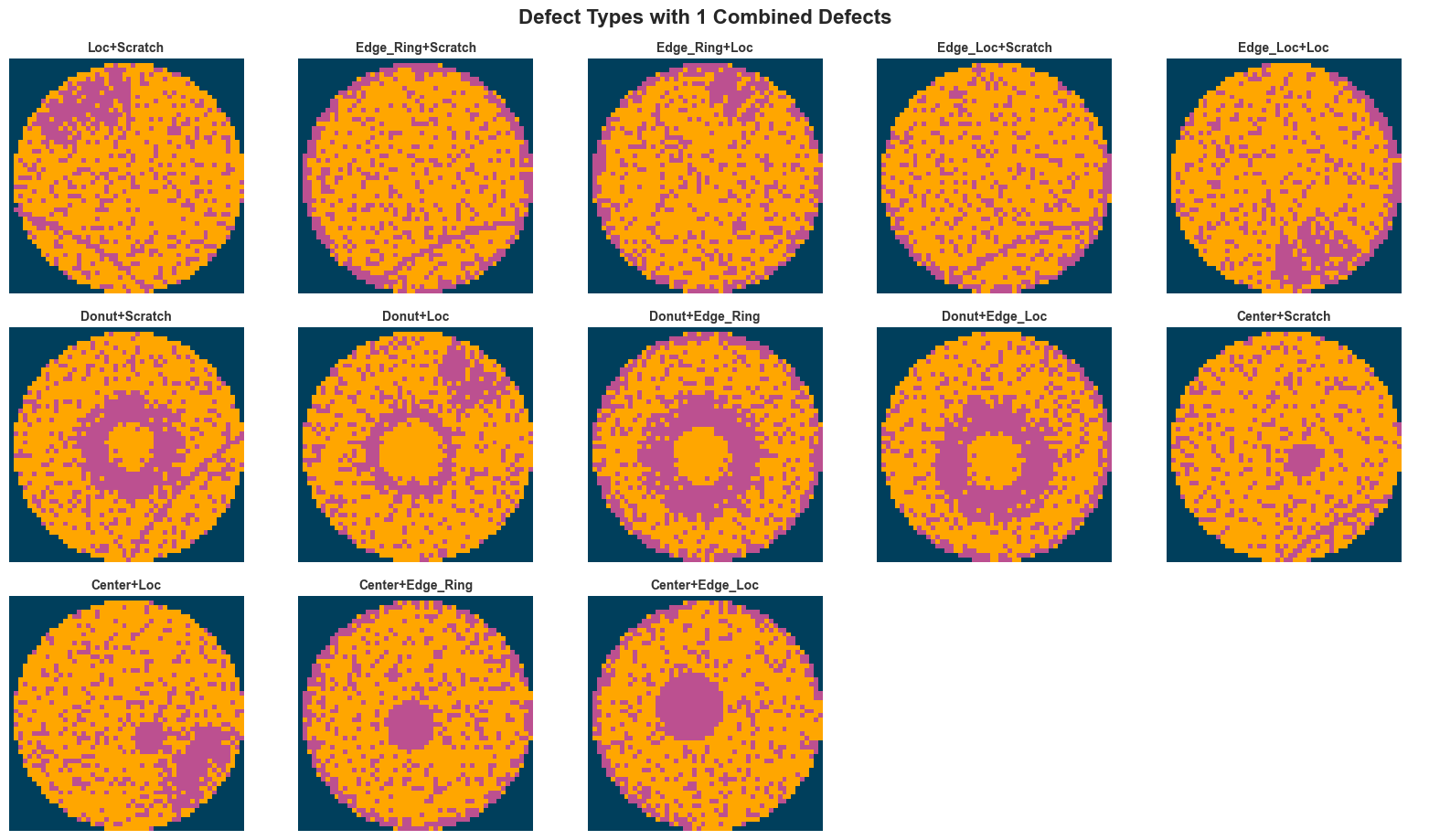
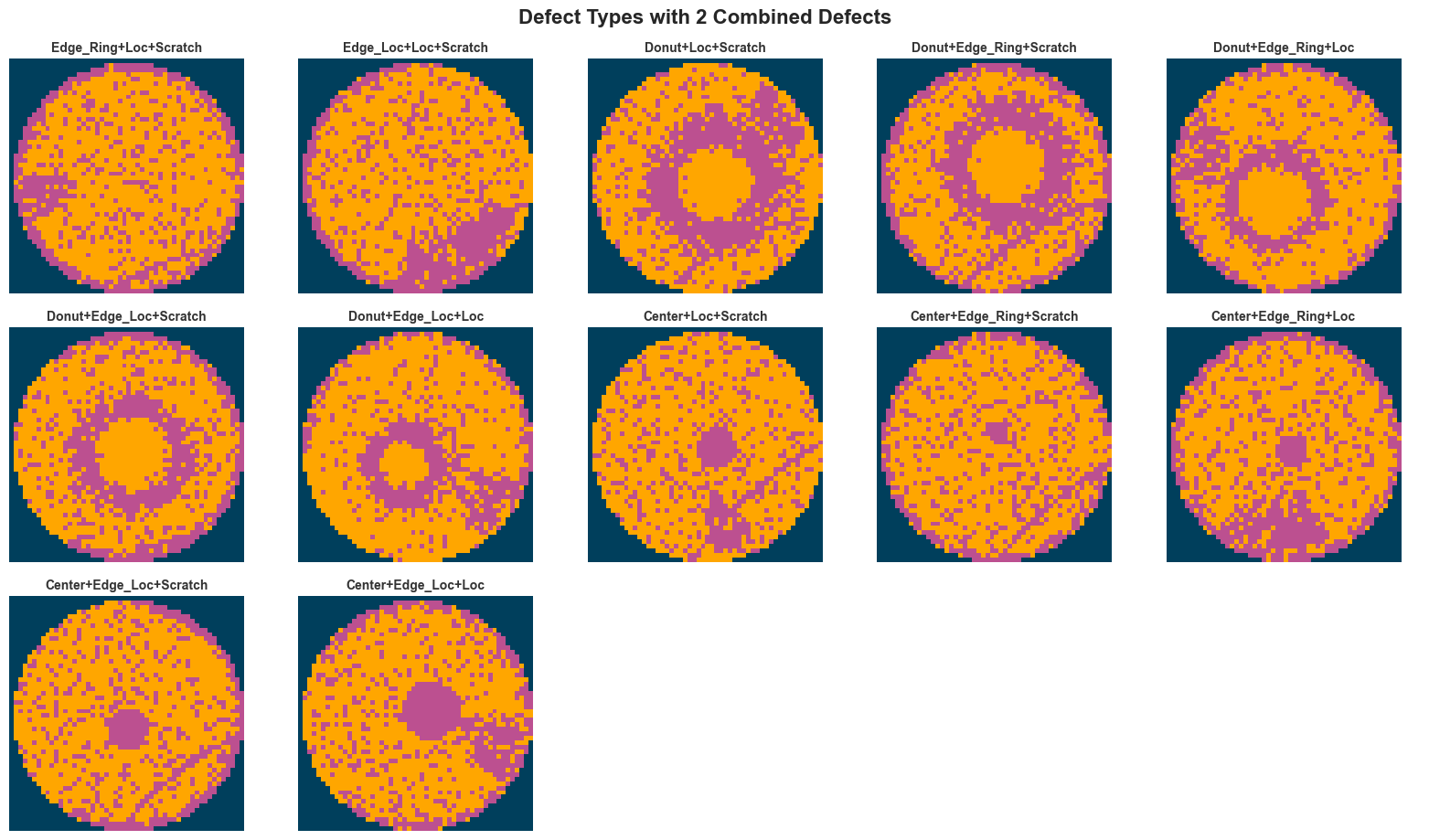
Step 1 — Data Preprocessing
Convert each (52, 52) image to (52, 52, 3) via one-hot encoding of the 3 pixel states: - Channel 0: blank (pixel == 0) - Channel 1: normal die (pixel == 1) - Channel 2: broken die (pixel == 2)
This preserves the categorical nature of the data — these are discrete states, not intensity values.
# One-hot encode pixel values: (N, 52, 52) -> (N, 52, 52, 3)
# Channel 0 = blank (0), Channel 1 = normal (1), Channel 2 = broken (2).
images_onehot = np.eye(3, dtype=np.float32)[images.astype(int)]
print("Original images shape:", images.shape)
print("One-hot encoded shape:", images_onehot.shape)
print("Labels shape:", labels.shape)
print("Dtype:", images_onehot.dtype)
# Verify encoding: show channel sums for first image
sample = images_onehot[0]
print("\nVerification — channel sums for first image:")
for ch in range(3):
print(f" Channel {ch} (pixel={ch}): {sample[:, :, ch].sum():.0f} pixels")Original images shape: (38015, 52, 52)
One-hot encoded shape: (38015, 52, 52, 3)
Labels shape: (38015, 8)
Dtype: float32
Verification — channel sums for first image:
Channel 0 (pixel=0): 643 pixels
Channel 1 (pixel=1): 1441 pixels
Channel 2 (pixel=2): 620 pixelsStep 2 — Train / Validation / Test Split
Using iterative stratification for multi-label data. Since sklearn’s train_test_split only supports single-label stratification, we convert the 8-dim one-hot vectors to string keys and stratify on those to ensure all 38 unique patterns are represented in every split.
Split ratio: 70% train / 15% validation / 15% test
# Create string keys for stratification (each unique label pattern = one stratum)
label_str_arr = np.array(["".join(map(str, map(int, row))) for row in labels])
# First split: 70% train, 30% temp
X_train, X_temp, y_train, y_temp, str_train, str_temp = train_test_split(
images_onehot,
labels,
label_str_arr,
test_size=0.30,
random_state=42,
stratify=label_str_arr,
)
# Second split: 50/50 of temp -> 15% val, 15% test
X_val, X_test, y_val, y_test, str_val, str_test = train_test_split(
X_temp,
y_temp,
str_temp,
test_size=0.50,
random_state=42,
stratify=str_temp,
)
print(f"Train: {X_train.shape[0]} samples")
print(f"Val: {X_val.shape[0]} samples")
print(f"Test: {X_test.shape[0]} samples")
# Verify: check that all 38 patterns are present in each split
for name, strs in [("Train", str_train), ("Val", str_val), ("Test", str_test)]:
unique_patterns = len(set(strs))
print(f" {name} — unique patterns: {unique_patterns}")
# Show per-label distribution across splits
base_labels = ["Center", "Donut", "Edge_Loc", "Edge_Ring", "Loc", "Near_Full", "Scratch", "Random"]
print("\nPer-label sample counts:")
header = f"{'Label':<12} {'Train':>6} {'Val':>6} {'Test':>6}"
print(header)
for i, name in enumerate(base_labels):
tr = y_train[:, i].sum()
va = y_val[:, i].sum()
te = y_test[:, i].sum()
print(f"{name:<12} {tr:>6.0f} {va:>6.0f} {te:>6.0f}")Train: 26610 samples
Val: 5702 samples
Test: 5703 samples
Train — unique patterns: 38
Val — unique patterns: 38
Test — unique patterns: 38
Per-label sample counts:
Label Train Val Test
Center 9100 1950 1950
Donut 8400 1800 1800
Edge_Loc 9100 1950 1950
Edge_Ring 8400 1800 1800
Loc 12600 2700 2700
Near_Full 104 22 23
Scratch 13300 2850 2850
Random 606 130 130Step 3 — Data Augmentation
Apply geometrically valid augmentations (rotations, flips, shifts) since wafer maps are rotationally symmetric. We create a tf.data pipeline with augmentation applied only during training.
We avoid elastic deformations and color jitter — the pixel values are discrete categorical states, not continuous intensities.
BATCH_SIZE = 32
AUTOTUNE = tf.data.AUTOTUNE
def augment(image, label):
"""Apply random geometric augmentations to a single image.
Since pixel values are one-hot encoded categorical states,
we only use spatial transforms (rotations, flips) that preserve
the discrete channel structure.
"""
# Random 90-degree rotations (k=0,1,2,3)
k = tf.random.uniform([], 0, 4, dtype=tf.int32)
image = tf.image.rot90(image, k=k)
# Random horizontal and vertical flips
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
return image, label
def build_dataset(x, y, *, shuffle=False, augment_fn=None, batch_size=BATCH_SIZE):
"""Create a tf.data.Dataset with optional shuffling and augmentation."""
ds = tf.data.Dataset.from_tensor_slices((x, y))
if shuffle:
ds = ds.shuffle(buffer_size=len(x), seed=42)
if augment_fn is not None:
ds = ds.map(augment_fn, num_parallel_calls=AUTOTUNE)
ds = ds.batch(batch_size).prefetch(AUTOTUNE)
return ds
# Build datasets
train_ds = build_dataset(X_train, y_train, shuffle=True, augment_fn=augment)
val_ds = build_dataset(X_val, y_val)
test_ds = build_dataset(X_test, y_test)
# Verify shapes
for batch_images, batch_labels in train_ds.take(1):
print("Batch images shape:", batch_images.shape)
print("Batch labels shape:", batch_labels.shape)
print("Image value range:", batch_images.numpy().min(), "to", batch_images.numpy().max())Batch images shape: (32, 52, 52, 3)
Batch labels shape: (32, 8)
Image value range: 0.0 to 1.02026-02-25 23:11:51.790128: I tensorflow/core/framework/local_rendezvous.cc:407] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequenceStep 4 — Focal Loss & Class Weights
Focal Loss down-weights easy/frequent examples and focuses learning on hard/rare ones. Combined with per-label weights (inversely proportional to frequency), this handles the severe imbalance between Normal (~1000) and Near_Full (~200).
\[FL(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)\]
- \(\alpha_t\): per-label weight (higher for rare classes)
- \(\gamma\): focusing parameter (typically 2.0)
# Compute per-label positive weights for the 8 base defect types
# Weight = (total_neg / total_pos) for each label column
n_samples = y_train.shape[0]
pos_counts = y_train.sum(axis=0) # shape (8,)
neg_counts = n_samples - pos_counts
# Avoid division by zero; labels with 0 positives get weight 1.0
pos_weights = np.where(pos_counts > 0, neg_counts / pos_counts, 1.0)
pos_weights_tensor = tf.constant(pos_weights, dtype=tf.float32)
print("Per-label positive weights:")
base_labels_names = ["Center", "Donut", "Edge_Loc", "Edge_Ring", "Loc", "Near_Full", "Scratch", "Random"]
for name, w, pc in zip(base_labels_names, pos_weights, pos_counts, strict=True):
print(f" {name:<12} weight={w:>6.2f} (pos_count={pc:.0f})")
class BinaryFocalLoss(tf.keras.losses.Loss):
"""Binary focal loss for multi-label classification.
Applies focal modulation per label to down-weight easy examples
and focus on hard/rare ones. Supports per-label positive weights.
"""
def __init__(self, gamma=2.0, pos_weight=None, **kwargs):
super().__init__(**kwargs)
self.gamma = gamma
self.pos_weight = pos_weight # shape (num_labels,)
def call(self, y_true, y_pred):
y_true = tf.cast(y_true, tf.float32)
y_pred = tf.clip_by_value(y_pred, 1e-7, 1.0 - 1e-7)
# Standard binary cross-entropy components
bce_pos = -y_true * tf.math.log(y_pred)
bce_neg = -(1.0 - y_true) * tf.math.log(1.0 - y_pred)
# Focal modulation: (1 - p_t)^gamma
p_t = y_true * y_pred + (1.0 - y_true) * (1.0 - y_pred)
focal_weight = tf.pow(1.0 - p_t, self.gamma)
# Apply per-label positive weights
alpha = y_true * self.pos_weight + (1.0 - y_true) * 1.0 if self.pos_weight is not None else 1.0
loss = focal_weight * alpha * (bce_pos + bce_neg)
return tf.reduce_mean(loss, axis=-1)
focal_loss = BinaryFocalLoss(gamma=2.0, pos_weight=pos_weights_tensor)
print("\nFocal Loss initialized with gamma=2.0")Per-label positive weights:
Center weight= 1.92 (pos_count=9100)
Donut weight= 2.17 (pos_count=8400)
Edge_Loc weight= 1.92 (pos_count=9100)
Edge_Ring weight= 2.17 (pos_count=8400)
Loc weight= 1.11 (pos_count=12600)
Near_Full weight=254.87 (pos_count=104)
Scratch weight= 1.00 (pos_count=13300)
Random weight= 42.91 (pos_count=606)
Focal Loss initialized with gamma=2.0Step 5 — Model 1A: Custom CNN
A lightweight CNN designed for the (52, 52, 3) input size: - 4 Conv2D blocks (32 → 64 → 128 → 256 filters), each with BatchNormalization + ReLU + MaxPooling - GlobalAveragePooling2D (reduces overfitting vs Flatten) - Dense(128) → Dropout(0.5) → Dense(8, sigmoid)
Output: 8 independent sigmoid activations for multi-label classification.
def build_custom_cnn(input_shape=(52, 52, 3), num_labels=8):
"""Build a lightweight CNN for multi-label wafer defect classification.
Architecture:
4 Conv blocks (32→64→128→256) with BatchNorm + ReLU + MaxPool
GlobalAveragePooling → Dense(128) → Dropout → Dense(num_labels, sigmoid)
"""
inputs = layers.Input(shape=input_shape, name="input_image")
x = inputs
for filters in [32, 64, 128, 256]:
x = layers.Conv2D(filters, (3, 3), padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(128, activation="relu")(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(num_labels, activation="sigmoid", name="output")(x)
return Model(inputs, outputs, name="custom_cnn")
model_cnn = build_custom_cnn()
model_cnn.summary()Model: "custom_cnn"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_image (InputLayer) │ (None, 52, 52, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d (Conv2D) │ (None, 52, 52, 32) │ 896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization │ (None, 52, 52, 32) │ 128 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation (Activation) │ (None, 52, 52, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 26, 26, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_1 (Conv2D) │ (None, 26, 26, 64) │ 18,496 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_1 │ (None, 26, 26, 64) │ 256 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_1 (Activation) │ (None, 26, 26, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 13, 13, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_2 (Conv2D) │ (None, 13, 13, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_2 │ (None, 13, 13, 128) │ 512 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_2 (Activation) │ (None, 13, 13, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_2 (MaxPooling2D) │ (None, 6, 6, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_3 (Conv2D) │ (None, 6, 6, 256) │ 295,168 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_3 │ (None, 6, 6, 256) │ 1,024 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_3 (Activation) │ (None, 6, 6, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_3 (MaxPooling2D) │ (None, 3, 3, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_average_pooling2d │ (None, 256) │ 0 │ │ (GlobalAveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 128) │ 32,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ output (Dense) │ (None, 8) │ 1,032 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 424,264 (1.62 MB)
Trainable params: 423,304 (1.61 MB)
Non-trainable params: 960 (3.75 KB)
Step 6 — Model 1B: Transfer Learning (MobileNetV2)
Project (52, 52, 4) → (52, 52, 3) with Conv2D, then resize to (224, 224, 3) to match MobileNetV2’s expected input. Use the pre-trained ImageNet backbone as a frozen feature extractor, with a custom multi-label classification head.
Note: ImageNet features (edges, textures) should still transfer reasonably well to wafer map patterns.
TARGET_SIZE = (224, 224)
def build_mobilenet_model(input_shape=(52, 52, 3), target_size=TARGET_SIZE, num_labels=8):
"""Build a MobileNetV2 transfer learning model for multi-label classification.
Projects (52,52,4) inputs to (52,52,3), then resizes to (224,224,3),
then passes through a frozen MobileNetV2 backbone with a custom head.
"""
inputs = layers.Input(shape=input_shape, name="input_image")
# Project 4 channels to 3 for MobileNetV2 compatibility
x = layers.Conv2D(3, (1, 1), padding="same", activation="relu")(inputs)
# Resize to MobileNetV2-compatible dimensions
x = layers.Resizing(target_size[0], target_size[1], interpolation="bilinear")(x)
# Frozen MobileNetV2 backbone
base_model = tf.keras.applications.MobileNetV2(
input_shape=(target_size[0], target_size[1], 3),
include_top=False,
weights="imagenet",
)
base_model.trainable = False
x = base_model(x, training=False)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(256, activation="relu")(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(num_labels, activation="sigmoid", name="output")(x)
return Model(inputs, outputs, name="mobilenet_transfer"), base_model
model_tl, base_model_tl = build_mobilenet_model()
model_tl.summary()
# Verify frozen layers
trainable = sum(1 for layer in base_model_tl.layers if layer.trainable)
total = len(base_model_tl.layers)
print(f"\nMobileNetV2 base: {trainable}/{total} trainable layers (should be 0/{total})")Model: "mobilenet_transfer"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_image (InputLayer) │ (None, 52, 52, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_4 (Conv2D) │ (None, 52, 52, 3) │ 12 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ resizing (Resizing) │ (None, 224, 224, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ mobilenetv2_1.00_224 │ (None, 7, 7, 1280) │ 2,257,984 │ │ (Functional) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_average_pooling2d_1 │ (None, 1280) │ 0 │ │ (GlobalAveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 256) │ 327,936 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_1 (Dropout) │ (None, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ output (Dense) │ (None, 8) │ 2,056 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 2,587,988 (9.87 MB)
Trainable params: 330,004 (1.26 MB)
Non-trainable params: 2,257,984 (8.61 MB)
MobileNetV2 base: 0/154 trainable layers (should be 0/154)Step 7 — Training
Both models are trained with: - Loss: Binary Focal Loss (gamma=2.0, per-label pos_weights) - Optimizer: Adam (lr=1e-3) - Callbacks: ReduceLROnPlateau(patience=5), EarlyStopping(patience=10, restore_best_weights=True) - Metrics: AUC (per-label average), binary accuracy - Epochs: up to 100 (early stopping will cut it short)
EPOCHS = 100
callbacks = [
tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_loss",
factor=0.5,
patience=5,
min_lr=1e-6,
verbose=1,
),
tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
patience=10,
restore_best_weights=True,
verbose=1,
),
]
metrics = [
tf.keras.metrics.AUC(name="auc", multi_label=True),
tf.keras.metrics.BinaryAccuracy(name="binary_acc"),
]Train Model 1A — Custom CNN
model_cnn.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=focal_loss,
metrics=metrics,
)
history_cnn = model_cnn.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=callbacks,
verbose=1,
)Epoch 1/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 28s 31ms/step - auc: 0.8536 - binary_acc: 0.7960 - loss: 0.1320 - val_auc: 0.8754 - val_binary_acc: 0.7561 - val_loss: 0.5910 - learning_rate: 0.0010 Epoch 2/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 26s 31ms/step - auc: 0.9065 - binary_acc: 0.8614 - loss: 0.0924 - val_auc: 0.9388 - val_binary_acc: 0.8665 - val_loss: 0.0668 - learning_rate: 0.0010 Epoch 3/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 31ms/step - auc: 0.9287 - binary_acc: 0.8939 - loss: 0.0646 - val_auc: 0.9453 - val_binary_acc: 0.9082 - val_loss: 0.0699 - learning_rate: 0.0010 Epoch 4/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 26s 31ms/step - auc: 0.9368 - binary_acc: 0.9064 - loss: 0.0573 - val_auc: 0.9541 - val_binary_acc: 0.9303 - val_loss: 0.0417 - learning_rate: 0.0010 Epoch 5/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 31ms/step - auc: 0.9429 - binary_acc: 0.9156 - loss: 0.0515 - val_auc: 0.8084 - val_binary_acc: 0.7108 - val_loss: 0.9099 - learning_rate: 0.0010 Epoch 6/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9495 - binary_acc: 0.9237 - loss: 0.0468 - val_auc: 0.9728 - val_binary_acc: 0.9419 - val_loss: 0.0419 - learning_rate: 0.0010 Epoch 7/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9410 - binary_acc: 0.9124 - loss: 0.0564 - val_auc: 0.9432 - val_binary_acc: 0.9027 - val_loss: 0.0579 - learning_rate: 0.0010 Epoch 8/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9459 - binary_acc: 0.9214 - loss: 0.0465 - val_auc: 0.9612 - val_binary_acc: 0.9277 - val_loss: 0.0577 - learning_rate: 0.0010 Epoch 9/100 831/832 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step - auc: 0.9423 - binary_acc: 0.9186 - loss: 0.0469 Epoch 9: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257. 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9482 - binary_acc: 0.9227 - loss: 0.0457 - val_auc: 0.9564 - val_binary_acc: 0.8997 - val_loss: 0.1008 - learning_rate: 0.0010 Epoch 10/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9532 - binary_acc: 0.9294 - loss: 0.0427 - val_auc: 0.9664 - val_binary_acc: 0.9436 - val_loss: 0.0291 - learning_rate: 5.0000e-04 Epoch 11/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9576 - binary_acc: 0.9337 - loss: 0.0418 - val_auc: 0.9809 - val_binary_acc: 0.9603 - val_loss: 0.0280 - learning_rate: 5.0000e-04 Epoch 12/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9632 - binary_acc: 0.9415 - loss: 0.0364 - val_auc: 0.9762 - val_binary_acc: 0.9445 - val_loss: 0.0325 - learning_rate: 5.0000e-04 Epoch 13/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9656 - binary_acc: 0.9427 - loss: 0.0398 - val_auc: 0.9858 - val_binary_acc: 0.9697 - val_loss: 0.0256 - learning_rate: 5.0000e-04 Epoch 14/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9678 - binary_acc: 0.9433 - loss: 0.0415 - val_auc: 0.9889 - val_binary_acc: 0.9719 - val_loss: 0.0245 - learning_rate: 5.0000e-04 Epoch 15/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9745 - binary_acc: 0.9515 - loss: 0.0348 - val_auc: 0.9884 - val_binary_acc: 0.9712 - val_loss: 0.0254 - learning_rate: 5.0000e-04 Epoch 16/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9797 - binary_acc: 0.9567 - loss: 0.0327 - val_auc: 0.9944 - val_binary_acc: 0.9838 - val_loss: 0.0175 - learning_rate: 5.0000e-04 Epoch 17/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9815 - binary_acc: 0.9572 - loss: 0.0346 - val_auc: 0.9951 - val_binary_acc: 0.9833 - val_loss: 0.0176 - learning_rate: 5.0000e-04 Epoch 18/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9850 - binary_acc: 0.9627 - loss: 0.0297 - val_auc: 0.9963 - val_binary_acc: 0.9855 - val_loss: 0.0164 - learning_rate: 5.0000e-04 Epoch 19/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9860 - binary_acc: 0.9648 - loss: 0.0300 - val_auc: 0.9952 - val_binary_acc: 0.9831 - val_loss: 0.0173 - learning_rate: 5.0000e-04 Epoch 20/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9878 - binary_acc: 0.9671 - loss: 0.0278 - val_auc: 0.9978 - val_binary_acc: 0.9895 - val_loss: 0.0150 - learning_rate: 5.0000e-04 Epoch 21/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9895 - binary_acc: 0.9698 - loss: 0.0261 - val_auc: 0.9977 - val_binary_acc: 0.9891 - val_loss: 0.0147 - learning_rate: 5.0000e-04 Epoch 22/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9879 - binary_acc: 0.9662 - loss: 0.0314 - val_auc: 0.9976 - val_binary_acc: 0.9898 - val_loss: 0.0152 - learning_rate: 5.0000e-04 Epoch 23/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9900 - binary_acc: 0.9702 - loss: 0.0271 - val_auc: 0.9977 - val_binary_acc: 0.9887 - val_loss: 0.0142 - learning_rate: 5.0000e-04 Epoch 24/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9901 - binary_acc: 0.9702 - loss: 0.0282 - val_auc: 0.9977 - val_binary_acc: 0.9898 - val_loss: 0.0130 - learning_rate: 5.0000e-04 Epoch 25/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9919 - binary_acc: 0.9727 - loss: 0.0261 - val_auc: 0.9972 - val_binary_acc: 0.9817 - val_loss: 0.0172 - learning_rate: 5.0000e-04 Epoch 26/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9921 - binary_acc: 0.9742 - loss: 0.0246 - val_auc: 0.9982 - val_binary_acc: 0.9819 - val_loss: 0.0209 - learning_rate: 5.0000e-04 Epoch 27/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9928 - binary_acc: 0.9751 - loss: 0.0229 - val_auc: 0.9985 - val_binary_acc: 0.9861 - val_loss: 0.0174 - learning_rate: 5.0000e-04 Epoch 28/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 31ms/step - auc: 0.9933 - binary_acc: 0.9758 - loss: 0.0234 - val_auc: 0.9977 - val_binary_acc: 0.9883 - val_loss: 0.0136 - learning_rate: 5.0000e-04 Epoch 29/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9935 - binary_acc: 0.9771 - loss: 0.0223 - val_auc: 0.9984 - val_binary_acc: 0.9923 - val_loss: 0.0126 - learning_rate: 5.0000e-04 Epoch 30/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9933 - binary_acc: 0.9765 - loss: 0.0230 - val_auc: 0.9987 - val_binary_acc: 0.9927 - val_loss: 0.0113 - learning_rate: 5.0000e-04 Epoch 31/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9940 - binary_acc: 0.9776 - loss: 0.0221 - val_auc: 0.9985 - val_binary_acc: 0.9930 - val_loss: 0.0125 - learning_rate: 5.0000e-04 Epoch 32/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9921 - binary_acc: 0.9744 - loss: 0.0255 - val_auc: 0.9988 - val_binary_acc: 0.9939 - val_loss: 0.0104 - learning_rate: 5.0000e-04 Epoch 33/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9934 - binary_acc: 0.9765 - loss: 0.0242 - val_auc: 0.9987 - val_binary_acc: 0.9941 - val_loss: 0.0102 - learning_rate: 5.0000e-04 Epoch 34/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9949 - binary_acc: 0.9797 - loss: 0.0203 - val_auc: 0.9988 - val_binary_acc: 0.9937 - val_loss: 0.0098 - learning_rate: 5.0000e-04 Epoch 35/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9952 - binary_acc: 0.9803 - loss: 0.0201 - val_auc: 0.9985 - val_binary_acc: 0.9891 - val_loss: 0.0150 - learning_rate: 5.0000e-04 Epoch 36/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9947 - binary_acc: 0.9791 - loss: 0.0229 - val_auc: 0.9933 - val_binary_acc: 0.9546 - val_loss: 0.0719 - learning_rate: 5.0000e-04 Epoch 37/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9951 - binary_acc: 0.9801 - loss: 0.0205 - val_auc: 0.9987 - val_binary_acc: 0.9904 - val_loss: 0.0136 - learning_rate: 5.0000e-04 Epoch 38/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9948 - binary_acc: 0.9793 - loss: 0.0216 - val_auc: 0.9978 - val_binary_acc: 0.9831 - val_loss: 0.0155 - learning_rate: 5.0000e-04 Epoch 39/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9953 - binary_acc: 0.9810 - loss: 0.0196 - val_auc: 0.9990 - val_binary_acc: 0.9943 - val_loss: 0.0084 - learning_rate: 5.0000e-04 Epoch 40/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9958 - binary_acc: 0.9819 - loss: 0.0183 - val_auc: 0.9989 - val_binary_acc: 0.9947 - val_loss: 0.0097 - learning_rate: 5.0000e-04 Epoch 41/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9955 - binary_acc: 0.9815 - loss: 0.0198 - val_auc: 0.9947 - val_binary_acc: 0.9675 - val_loss: 0.0264 - learning_rate: 5.0000e-04 Epoch 42/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9958 - binary_acc: 0.9818 - loss: 0.0185 - val_auc: 0.9990 - val_binary_acc: 0.9930 - val_loss: 0.0108 - learning_rate: 5.0000e-04 Epoch 43/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9960 - binary_acc: 0.9821 - loss: 0.0181 - val_auc: 0.9989 - val_binary_acc: 0.9935 - val_loss: 0.0102 - learning_rate: 5.0000e-04 Epoch 44/100 830/832 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step - auc: 0.9953 - binary_acc: 0.9821 - loss: 0.0184 Epoch 44: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628. 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9959 - binary_acc: 0.9818 - loss: 0.0189 - val_auc: 0.9991 - val_binary_acc: 0.9955 - val_loss: 0.0087 - learning_rate: 5.0000e-04 Epoch 45/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9966 - binary_acc: 0.9837 - loss: 0.0167 - val_auc: 0.9991 - val_binary_acc: 0.9954 - val_loss: 0.0088 - learning_rate: 2.5000e-04 Epoch 46/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9966 - binary_acc: 0.9836 - loss: 0.0167 - val_auc: 0.9991 - val_binary_acc: 0.9941 - val_loss: 0.0089 - learning_rate: 2.5000e-04 Epoch 47/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9967 - binary_acc: 0.9841 - loss: 0.0161 - val_auc: 0.9991 - val_binary_acc: 0.9949 - val_loss: 0.0102 - learning_rate: 2.5000e-04 Epoch 48/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9967 - binary_acc: 0.9845 - loss: 0.0158 - val_auc: 0.9991 - val_binary_acc: 0.9935 - val_loss: 0.0086 - learning_rate: 2.5000e-04 Epoch 49/100 831/832 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step - auc: 0.9942 - binary_acc: 0.9852 - loss: 0.0149 Epoch 49: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814. 832/832 ━━━━━━━━━━━━━━━━━━━━ 25s 30ms/step - auc: 0.9968 - binary_acc: 0.9846 - loss: 0.0158 - val_auc: 0.9991 - val_binary_acc: 0.9956 - val_loss: 0.0085 - learning_rate: 2.5000e-04 Epoch 49: early stopping Restoring model weights from the end of the best epoch: 39.
Train Model 1B — MobileNetV2 Transfer Learning
# Need fresh metrics instances (Keras metrics are stateful)
metrics_tl = [
tf.keras.metrics.AUC(name="auc", multi_label=True),
tf.keras.metrics.BinaryAccuracy(name="binary_acc"),
]
model_tl.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=BinaryFocalLoss(gamma=2.0, pos_weight=pos_weights_tensor),
metrics=metrics_tl,
)
# Fresh callbacks (they carry state from previous training)
callbacks_tl = [
tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_loss",
factor=0.5,
patience=5,
min_lr=1e-6,
verbose=1,
),
tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
patience=10,
restore_best_weights=True,
verbose=1,
),
]
history_tl = model_tl.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=callbacks_tl,
verbose=1,
)Epoch 1/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 200s 237ms/step - auc: 0.8527 - binary_acc: 0.8056 - loss: 0.1289 - val_auc: 0.9175 - val_binary_acc: 0.8686 - val_loss: 0.0841 - learning_rate: 0.0010 Epoch 2/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 234ms/step - auc: 0.8791 - binary_acc: 0.8255 - loss: 0.1177 - val_auc: 0.9345 - val_binary_acc: 0.8660 - val_loss: 0.0771 - learning_rate: 0.0010 Epoch 3/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8902 - binary_acc: 0.8374 - loss: 0.1176 - val_auc: 0.9456 - val_binary_acc: 0.8943 - val_loss: 0.0790 - learning_rate: 0.0010 Epoch 4/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8890 - binary_acc: 0.8339 - loss: 0.1045 - val_auc: 0.9419 - val_binary_acc: 0.8859 - val_loss: 0.0827 - learning_rate: 0.0010 Epoch 5/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 234ms/step - auc: 0.8899 - binary_acc: 0.8352 - loss: 0.1123 - val_auc: 0.9414 - val_binary_acc: 0.8934 - val_loss: 0.0831 - learning_rate: 0.0010 Epoch 6/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 237ms/step - auc: 0.8891 - binary_acc: 0.8374 - loss: 0.1006 - val_auc: 0.9497 - val_binary_acc: 0.8972 - val_loss: 0.0742 - learning_rate: 0.0010 Epoch 7/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.8989 - binary_acc: 0.8456 - loss: 0.0965 - val_auc: 0.9539 - val_binary_acc: 0.9046 - val_loss: 0.0756 - learning_rate: 0.0010 Epoch 8/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8871 - binary_acc: 0.8331 - loss: 0.1009 - val_auc: 0.9494 - val_binary_acc: 0.9078 - val_loss: 0.0748 - learning_rate: 0.0010 Epoch 9/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.8932 - binary_acc: 0.8436 - loss: 0.0898 - val_auc: 0.9516 - val_binary_acc: 0.9001 - val_loss: 0.0727 - learning_rate: 0.0010 Epoch 10/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8835 - binary_acc: 0.8316 - loss: 0.1015 - val_auc: 0.9463 - val_binary_acc: 0.8953 - val_loss: 0.0829 - learning_rate: 0.0010 Epoch 11/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.8871 - binary_acc: 0.8325 - loss: 0.0982 - val_auc: 0.9504 - val_binary_acc: 0.8992 - val_loss: 0.0716 - learning_rate: 0.0010 Epoch 12/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.8952 - binary_acc: 0.8430 - loss: 0.0898 - val_auc: 0.9603 - val_binary_acc: 0.9114 - val_loss: 0.0694 - learning_rate: 0.0010 Epoch 13/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 198s 238ms/step - auc: 0.9003 - binary_acc: 0.8505 - loss: 0.0863 - val_auc: 0.9581 - val_binary_acc: 0.9147 - val_loss: 0.0684 - learning_rate: 0.0010 Epoch 14/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8974 - binary_acc: 0.8484 - loss: 0.0946 - val_auc: 0.9607 - val_binary_acc: 0.9128 - val_loss: 0.0717 - learning_rate: 0.0010 Epoch 15/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.8842 - binary_acc: 0.8297 - loss: 0.1024 - val_auc: 0.9475 - val_binary_acc: 0.8982 - val_loss: 0.0806 - learning_rate: 0.0010 Epoch 16/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 237ms/step - auc: 0.8805 - binary_acc: 0.8272 - loss: 0.0945 - val_auc: 0.9211 - val_binary_acc: 0.8801 - val_loss: 0.0782 - learning_rate: 0.0010 Epoch 17/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.8781 - binary_acc: 0.8258 - loss: 0.0964 - val_auc: 0.9386 - val_binary_acc: 0.8855 - val_loss: 0.0795 - learning_rate: 0.0010 Epoch 18/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 215ms/step - auc: 0.8826 - binary_acc: 0.8314 - loss: 0.0955 Epoch 18: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257. 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.8848 - binary_acc: 0.8322 - loss: 0.0927 - val_auc: 0.9366 - val_binary_acc: 0.8798 - val_loss: 0.0779 - learning_rate: 0.0010 Epoch 19/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.8928 - binary_acc: 0.8414 - loss: 0.0902 - val_auc: 0.9542 - val_binary_acc: 0.9056 - val_loss: 0.0728 - learning_rate: 5.0000e-04 Epoch 20/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9012 - binary_acc: 0.8509 - loss: 0.0848 - val_auc: 0.9526 - val_binary_acc: 0.9077 - val_loss: 0.0702 - learning_rate: 5.0000e-04 Epoch 21/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 237ms/step - auc: 0.9047 - binary_acc: 0.8546 - loss: 0.0867 - val_auc: 0.9595 - val_binary_acc: 0.9111 - val_loss: 0.0697 - learning_rate: 5.0000e-04 Epoch 22/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 237ms/step - auc: 0.9070 - binary_acc: 0.8568 - loss: 0.0866 - val_auc: 0.9599 - val_binary_acc: 0.9057 - val_loss: 0.0737 - learning_rate: 5.0000e-04 Epoch 23/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9107 - binary_acc: 0.8592 - loss: 0.0811 - val_auc: 0.9597 - val_binary_acc: 0.9225 - val_loss: 0.0648 - learning_rate: 5.0000e-04 Epoch 24/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9147 - binary_acc: 0.8638 - loss: 0.0815 - val_auc: 0.9652 - val_binary_acc: 0.9189 - val_loss: 0.0644 - learning_rate: 5.0000e-04 Epoch 25/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9208 - binary_acc: 0.8710 - loss: 0.0774 - val_auc: 0.9645 - val_binary_acc: 0.9223 - val_loss: 0.0598 - learning_rate: 5.0000e-04 Epoch 26/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 236ms/step - auc: 0.9165 - binary_acc: 0.8671 - loss: 0.0925 - val_auc: 0.9585 - val_binary_acc: 0.9116 - val_loss: 0.0704 - learning_rate: 5.0000e-04 Epoch 27/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9096 - binary_acc: 0.8584 - loss: 0.0878 - val_auc: 0.9581 - val_binary_acc: 0.9107 - val_loss: 0.0666 - learning_rate: 5.0000e-04 Epoch 28/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9157 - binary_acc: 0.8640 - loss: 0.0789 - val_auc: 0.9644 - val_binary_acc: 0.9192 - val_loss: 0.0637 - learning_rate: 5.0000e-04 Epoch 29/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9202 - binary_acc: 0.8692 - loss: 0.0780 - val_auc: 0.9648 - val_binary_acc: 0.9175 - val_loss: 0.0639 - learning_rate: 5.0000e-04 Epoch 30/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 215ms/step - auc: 0.9213 - binary_acc: 0.8696 - loss: 0.0777 Epoch 30: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628. 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9206 - binary_acc: 0.8690 - loss: 0.0777 - val_auc: 0.9661 - val_binary_acc: 0.9247 - val_loss: 0.0618 - learning_rate: 5.0000e-04 Epoch 31/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 237ms/step - auc: 0.9234 - binary_acc: 0.8729 - loss: 0.0745 - val_auc: 0.9650 - val_binary_acc: 0.9239 - val_loss: 0.0621 - learning_rate: 2.5000e-04 Epoch 32/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9240 - binary_acc: 0.8725 - loss: 0.0761 - val_auc: 0.9664 - val_binary_acc: 0.9224 - val_loss: 0.0620 - learning_rate: 2.5000e-04 Epoch 33/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9250 - binary_acc: 0.8739 - loss: 0.0737 - val_auc: 0.9655 - val_binary_acc: 0.9230 - val_loss: 0.0619 - learning_rate: 2.5000e-04 Epoch 34/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9248 - binary_acc: 0.8738 - loss: 0.0732 - val_auc: 0.9672 - val_binary_acc: 0.9222 - val_loss: 0.0590 - learning_rate: 2.5000e-04 Epoch 35/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9258 - binary_acc: 0.8743 - loss: 0.0740 - val_auc: 0.9669 - val_binary_acc: 0.9204 - val_loss: 0.0602 - learning_rate: 2.5000e-04 Epoch 36/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9251 - binary_acc: 0.8724 - loss: 0.0760 - val_auc: 0.9687 - val_binary_acc: 0.9304 - val_loss: 0.0571 - learning_rate: 2.5000e-04 Epoch 37/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9263 - binary_acc: 0.8744 - loss: 0.0735 - val_auc: 0.9685 - val_binary_acc: 0.9241 - val_loss: 0.0578 - learning_rate: 2.5000e-04 Epoch 38/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9285 - binary_acc: 0.8784 - loss: 0.0717 - val_auc: 0.9674 - val_binary_acc: 0.9264 - val_loss: 0.0562 - learning_rate: 2.5000e-04 Epoch 39/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9257 - binary_acc: 0.8750 - loss: 0.0764 - val_auc: 0.9679 - val_binary_acc: 0.9265 - val_loss: 0.0584 - learning_rate: 2.5000e-04 Epoch 40/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9297 - binary_acc: 0.8781 - loss: 0.0740 - val_auc: 0.9677 - val_binary_acc: 0.9219 - val_loss: 0.0570 - learning_rate: 2.5000e-04 Epoch 41/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9295 - binary_acc: 0.8793 - loss: 0.0722 - val_auc: 0.9672 - val_binary_acc: 0.9265 - val_loss: 0.0573 - learning_rate: 2.5000e-04 Epoch 42/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 234ms/step - auc: 0.9301 - binary_acc: 0.8788 - loss: 0.0723 - val_auc: 0.9705 - val_binary_acc: 0.9298 - val_loss: 0.0569 - learning_rate: 2.5000e-04 Epoch 43/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9317 - binary_acc: 0.8819 - loss: 0.0707 - val_auc: 0.9688 - val_binary_acc: 0.9310 - val_loss: 0.0555 - learning_rate: 2.5000e-04 Epoch 44/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9297 - binary_acc: 0.8794 - loss: 0.0721 - val_auc: 0.9710 - val_binary_acc: 0.9328 - val_loss: 0.0573 - learning_rate: 2.5000e-04 Epoch 45/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 234ms/step - auc: 0.9309 - binary_acc: 0.8809 - loss: 0.0710 - val_auc: 0.9703 - val_binary_acc: 0.9278 - val_loss: 0.0581 - learning_rate: 2.5000e-04 Epoch 46/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9323 - binary_acc: 0.8817 - loss: 0.0712 - val_auc: 0.9707 - val_binary_acc: 0.9289 - val_loss: 0.0572 - learning_rate: 2.5000e-04 Epoch 47/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 197s 236ms/step - auc: 0.9314 - binary_acc: 0.8811 - loss: 0.0708 - val_auc: 0.9714 - val_binary_acc: 0.9279 - val_loss: 0.0557 - learning_rate: 2.5000e-04 Epoch 48/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 215ms/step - auc: 0.9311 - binary_acc: 0.8805 - loss: 0.0781 Epoch 48: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814. 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9319 - binary_acc: 0.8809 - loss: 0.0740 - val_auc: 0.9715 - val_binary_acc: 0.9299 - val_loss: 0.0563 - learning_rate: 2.5000e-04 Epoch 49/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9328 - binary_acc: 0.8828 - loss: 0.0706 - val_auc: 0.9715 - val_binary_acc: 0.9314 - val_loss: 0.0557 - learning_rate: 1.2500e-04 Epoch 50/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9334 - binary_acc: 0.8824 - loss: 0.0698 - val_auc: 0.9716 - val_binary_acc: 0.9320 - val_loss: 0.0563 - learning_rate: 1.2500e-04 Epoch 51/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 195s 235ms/step - auc: 0.9331 - binary_acc: 0.8824 - loss: 0.0697 - val_auc: 0.9706 - val_binary_acc: 0.9276 - val_loss: 0.0560 - learning_rate: 1.2500e-04 Epoch 52/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 236ms/step - auc: 0.9344 - binary_acc: 0.8842 - loss: 0.0689 - val_auc: 0.9710 - val_binary_acc: 0.9301 - val_loss: 0.0571 - learning_rate: 1.2500e-04 Epoch 53/100 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 216ms/step - auc: 0.9328 - binary_acc: 0.8841 - loss: 0.0693 Epoch 53: ReduceLROnPlateau reducing learning rate to 6.25000029685907e-05. 832/832 ━━━━━━━━━━━━━━━━━━━━ 196s 235ms/step - auc: 0.9337 - binary_acc: 0.8842 - loss: 0.0694 - val_auc: 0.9717 - val_binary_acc: 0.9306 - val_loss: 0.0556 - learning_rate: 1.2500e-04 Epoch 53: early stopping Restoring model weights from the end of the best epoch: 43.
Step 8 — Phase 1 Evaluation & Comparison
Compare both models on the test set using: - Training history plots (loss & AUC) - Per-label Precision, Recall, F1 - Macro F1 summary
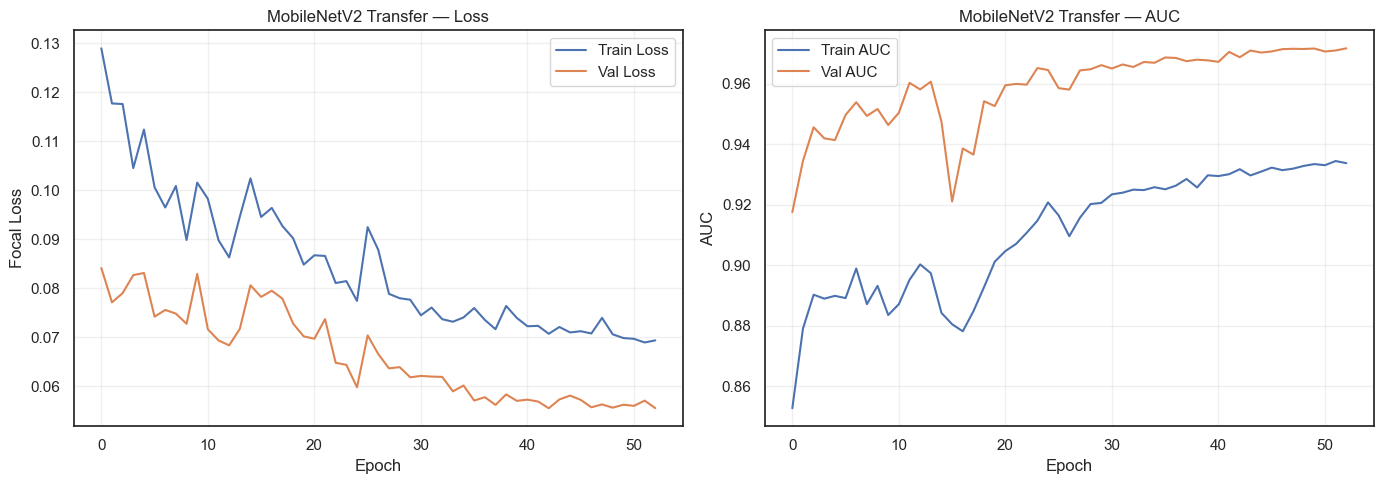
def plot_training_history(history, model_name):
"""Plot loss and AUC curves for training and validation."""
_fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Loss
axes[0].plot(history.history["loss"], label="Train Loss")
axes[0].plot(history.history["val_loss"], label="Val Loss")
axes[0].set_title(f"{model_name} — Loss")
axes[0].set_xlabel("Epoch")
axes[0].set_ylabel("Focal Loss")
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# AUC
axes[1].plot(history.history["auc"], label="Train AUC")
axes[1].plot(history.history["val_auc"], label="Val AUC")
axes[1].set_title(f"{model_name} — AUC")
axes[1].set_xlabel("Epoch")
axes[1].set_ylabel("AUC")
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
plot_training_history(history_cnn, "Custom CNN")
plot_training_history(history_tl, "MobileNetV2 Transfer")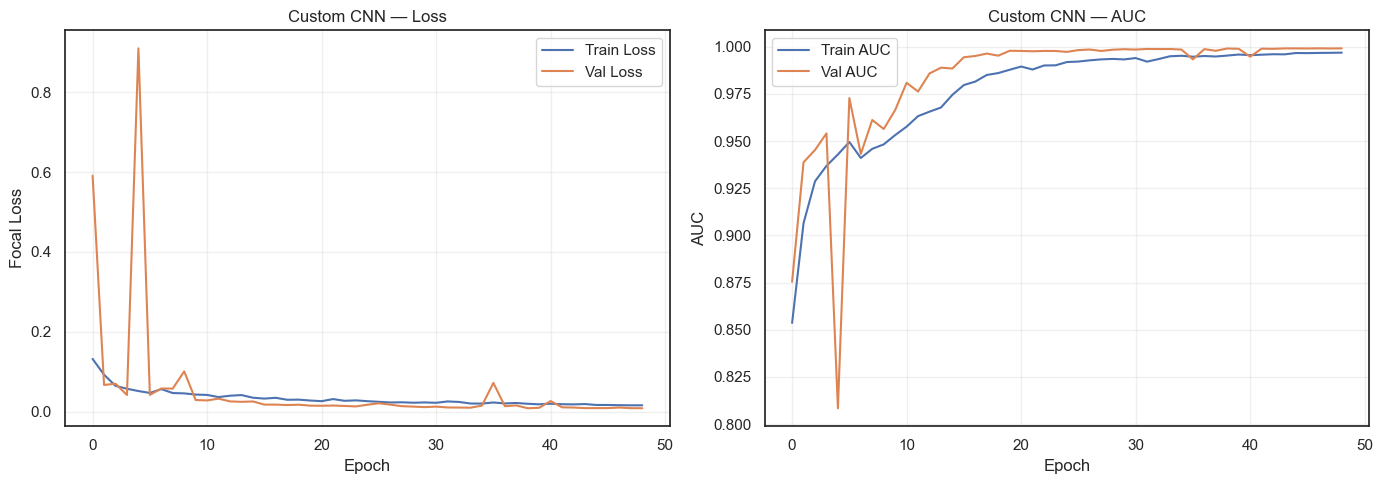
from sklearn.metrics import classification_report, f1_score
THRESHOLD = 0.5
base_labels_all = ["Center", "Donut", "Edge_Loc", "Edge_Ring", "Loc", "Near_Full", "Scratch", "Random"]
def evaluate_multilabel(model, dataset, y_true, model_name):
"""Evaluate a multi-label model: per-label precision/recall/F1 + macro F1."""
y_pred_prob = model.predict(dataset, verbose=0)
y_pred = (y_pred_prob >= THRESHOLD).astype(int)
separator = "=" * 60
print(f"\n{separator}")
print(f" {model_name} — Test Set Results (threshold={THRESHOLD})")
print(separator)
report = classification_report(
y_true,
y_pred,
target_names=base_labels_all,
zero_division=0,
output_dict=True,
)
print(
classification_report(
y_true,
y_pred,
target_names=base_labels_all,
zero_division=0,
)
)
macro_f1 = f1_score(y_true, y_pred, average="macro", zero_division=0)
weighted_f1 = f1_score(y_true, y_pred, average="weighted", zero_division=0)
print(f"Macro F1: {macro_f1:.4f}")
print(f"Weighted F1: {weighted_f1:.4f}")
return y_pred, y_pred_prob, report
y_pred_cnn, y_prob_cnn, report_cnn = evaluate_multilabel(model_cnn, test_ds, y_test, "Custom CNN")
y_pred_tl, y_prob_tl, report_tl = evaluate_multilabel(model_tl, test_ds, y_test, "MobileNetV2 Transfer")
============================================================
Custom CNN — Test Set Results (threshold=0.5)
============================================================
precision recall f1-score support
Center 1.00 1.00 1.00 1950
Donut 1.00 1.00 1.00 1800
Edge_Loc 0.98 0.99 0.99 1950
Edge_Ring 0.99 0.99 0.99 1800
Loc 1.00 0.99 0.99 2700
Near_Full 0.82 1.00 0.90 23
Scratch 0.97 0.98 0.98 2850
Random 0.94 1.00 0.97 130
micro avg 0.99 0.99 0.99 13203
macro avg 0.96 0.99 0.98 13203
weighted avg 0.99 0.99 0.99 13203
samples avg 0.96 0.97 0.96 13203
Macro F1: 0.9779
Weighted F1: 0.9905
============================================================
MobileNetV2 Transfer — Test Set Results (threshold=0.5)
============================================================
precision recall f1-score support
Center 0.97 0.97 0.97 1950
Donut 1.00 1.00 1.00 1800
Edge_Loc 0.67 0.83 0.75 1950
Edge_Ring 0.80 0.97 0.88 1800
Loc 0.87 0.91 0.89 2700
Near_Full 0.79 1.00 0.88 23
Scratch 0.84 0.85 0.84 2850
Random 0.98 1.00 0.99 130
micro avg 0.85 0.91 0.88 13203
macro avg 0.87 0.94 0.90 13203
weighted avg 0.86 0.91 0.88 13203
samples avg 0.85 0.89 0.85 13203
Macro F1: 0.8998
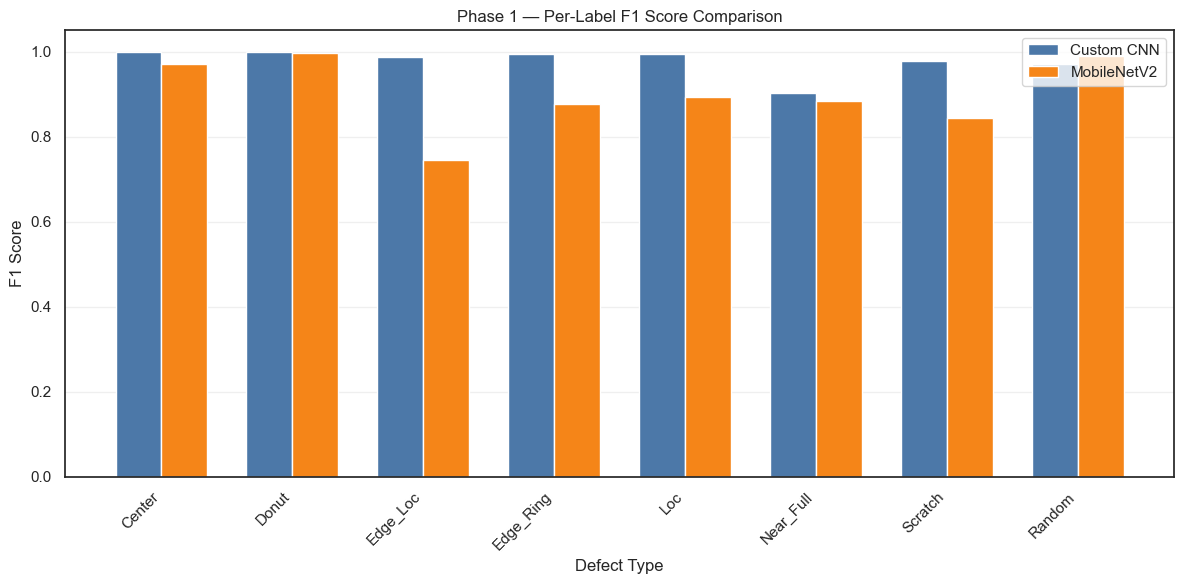
Weighted F1: 0.8847# Side-by-side F1 comparison per label
comparison_data = []
for label_name in base_labels_all:
comparison_data.append({
"Defect Type": label_name,
"Custom CNN F1": report_cnn[label_name]["f1-score"],
"MobileNetV2 F1": report_tl[label_name]["f1-score"],
})
comparison_df = pd.DataFrame(comparison_data)
# Add macro averages
comparison_df = pd.concat(
[
comparison_df,
pd.DataFrame([
{
"Defect Type": "MACRO AVG",
"Custom CNN F1": report_cnn["macro avg"]["f1-score"],
"MobileNetV2 F1": report_tl["macro avg"]["f1-score"],
}
]),
],
ignore_index=True,
)
display(
comparison_df.style.format({"Custom CNN F1": "{:.4f}", "MobileNetV2 F1": "{:.4f}"}).highlight_max(
subset=["Custom CNN F1", "MobileNetV2 F1"],
axis=1,
color="lightgreen",
)
)
# Bar chart comparison
_fig, ax = plt.subplots(figsize=(12, 6))
x = np.arange(len(base_labels_all))
width = 0.35
ax.bar(
x - width / 2, [report_cnn[lbl]["f1-score"] for lbl in base_labels_all], width, label="Custom CNN", color="#4C78A8"
)
ax.bar(
x + width / 2, [report_tl[lbl]["f1-score"] for lbl in base_labels_all], width, label="MobileNetV2", color="#F58518"
)
ax.set_xlabel("Defect Type")
ax.set_ylabel("F1 Score")
ax.set_title("Phase 1 — Per-Label F1 Score Comparison")
ax.set_xticks(x)
ax.set_xticklabels(base_labels_all, rotation=45, ha="right")
ax.legend()
ax.grid(True, alpha=0.3, axis="y")
plt.tight_layout()
plt.show()| Defect Type | Custom CNN F1 | MobileNetV2 F1 | |
|---|---|---|---|
| 0 | Center | 1.0000 | 0.9704 |
| 1 | Donut | 1.0000 | 0.9964 |
| 2 | Edge_Loc | 0.9870 | 0.7456 |
| 3 | Edge_Ring | 0.9936 | 0.8773 |
| 4 | Loc | 0.9941 | 0.8927 |
| 5 | Near_Full | 0.9020 | 0.8846 |
| 6 | Scratch | 0.9768 | 0.8430 |
| 7 | Random | 0.9701 | 0.9886 |
| 8 | MACRO AVG | 0.9779 | 0.8998 |
Phase 2 — Multi-Class Classification (All 38 Defect Patterns)
Reuse the best-performing Phase 1 convolutional backbone as a frozen feature extractor and replace the classification head with a 38-class softmax output.
Strategy: 1. Select the best Phase 1 model based on Macro F1 2. Freeze its conv layers, replace the head 3. Two-stage training: head-only (lr=1e-3) → fine-tune last conv blocks (lr=1e-5)
Step 9 — Encode All 38 Pattern Labels
Convert each 8-dim one-hot vector to a single integer class ID (0–37) for multi-class softmax classification. Compute class weights using sklearn to handle the severe imbalance.
from sklearn.utils.class_weight import compute_class_weight
# Build a mapping from one-hot string key → integer class ID
unique_patterns = sorted(label_mapping.keys())
pattern_to_id = {pattern: idx for idx, pattern in enumerate(unique_patterns)}
id_to_pattern = {idx: label_mapping[pattern] for pattern, idx in pattern_to_id.items()}
NUM_CLASSES = len(unique_patterns)
print(f"Number of unique defect patterns: {NUM_CLASSES}")
print("\nClass ID → Pattern Name:")
for cid, name in id_to_pattern.items():
print(f" {cid:>2}: {name}")
# Convert all labels to integer class IDs
y_class_all = np.array([pattern_to_id["".join(map(str, map(int, row)))] for row in labels])
# Split using the same indices — recreate from label_str_arr
y_class_train = np.array([pattern_to_id[s] for s in str_train])
y_class_val = np.array([pattern_to_id[s] for s in str_val])
y_class_test = np.array([pattern_to_id[s] for s in str_test])
print(f"\nTrain class IDs shape: {y_class_train.shape}")
print(f"Val class IDs shape: {y_class_val.shape}")
print(f"Test class IDs shape: {y_class_test.shape}")
# Compute class weights to handle imbalance
class_weights_arr = compute_class_weight(
class_weight="balanced",
classes=np.arange(NUM_CLASSES),
y=y_class_train,
)
class_weights_dict = dict(enumerate(class_weights_arr))
print("\nClass weights (top 5 highest):")
for cid, w in sorted(class_weights_dict.items(), key=lambda x: x[1], reverse=True)[:5]:
print(f" {id_to_pattern[cid]:<35} weight={w:.3f}")Number of unique defect patterns: 38
Class ID → Pattern Name:
0: Normal
1: Random
2: Scratch
3: Near_Full
4: Loc
5: Loc+Scratch
6: Edge_Ring
7: Edge_Ring+Scratch
8: Edge_Ring+Loc
9: Edge_Ring+Loc+Scratch
10: Edge_Loc
11: Edge_Loc+Scratch
12: Edge_Loc+Loc
13: Edge_Loc+Loc+Scratch
14: Donut
15: Donut+Scratch
16: Donut+Loc
17: Donut+Loc+Scratch
18: Donut+Edge_Ring
19: Donut+Edge_Ring+Scratch
20: Donut+Edge_Ring+Loc
21: Donut+Edge_Ring+Loc+Scratch
22: Donut+Edge_Loc
23: Donut+Edge_Loc+Scratch
24: Donut+Edge_Loc+Loc
25: Donut+Edge_Loc+Loc+Scratch
26: Center
27: Center+Scratch
28: Center+Loc
29: Center+Loc+Scratch
30: Center+Edge_Ring
31: Center+Edge_Ring+Scratch
32: Center+Edge_Ring+Loc
33: Center+Edge_Ring+Loc+Scratch
34: Center+Edge_Loc
35: Center+Edge_Loc+Scratch
36: Center+Edge_Loc+Loc
37: Center+Edge_Loc+Loc+Scratch
Train class IDs shape: (26610,)
Val class IDs shape: (5702,)
Test class IDs shape: (5703,)
Class weights (top 5 highest):
Near_Full weight=6.733
Random weight=1.156
Normal weight=1.000
Scratch weight=1.000
Loc weight=1.000Step 10 — Phase 2 Models: Backbone Reuse
Build Phase 2 models by reusing the convolutional backbones from both Phase 1 models: 1. Freeze all conv layers from the Phase 1 model 2. Replace the Dense(8, sigmoid) head with Dense(128, relu) → Dropout → Dense(38, softmax) 3. Build separate datasets with integer class labels for sparse_categorical_crossentropy
# Build Phase 2 datasets with integer class labels
train_ds_p2 = build_dataset(X_train, y_class_train, shuffle=True, augment_fn=augment)
val_ds_p2 = build_dataset(X_val, y_class_val)
test_ds_p2 = build_dataset(X_test, y_class_test)
# Verify shapes
for batch_images, batch_labels in train_ds_p2.take(1):
print("Phase 2 batch images shape:", batch_images.shape)
print("Phase 2 batch labels shape:", batch_labels.shape)
print("Sample labels:", batch_labels[:5].numpy())
def build_phase2_from_backbone(phase1_model, num_classes=NUM_CLASSES, model_name="phase2"):
"""Reuse Phase 1 conv backbone, freeze it, and add a new 38-class softmax head.
Extracts the feature extractor (everything up to GlobalAveragePooling2D output)
from the Phase 1 model and attaches a new classification head.
"""
# Find the GlobalAveragePooling2D layer output in the Phase 1 model
gap_layer = None
for layer in phase1_model.layers:
if isinstance(layer, layers.GlobalAveragePooling2D):
gap_layer = layer
break
if gap_layer is None:
msg = "Could not find GlobalAveragePooling2D in Phase 1 model"
raise ValueError(msg)
# Build feature extractor: input → GAP output
feature_extractor = Model(
inputs=phase1_model.input,
outputs=gap_layer.output,
name=f"{model_name}_backbone",
)
# Freeze all backbone layers
for layer in feature_extractor.layers:
layer.trainable = False
# New classification head
inputs = layers.Input(shape=phase1_model.input_shape[1:], name="input_image")
x = feature_extractor(inputs, training=False)
x = layers.Dense(128, activation="relu")(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(num_classes, activation="softmax", name="output_38")(x)
return Model(inputs, outputs, name=model_name), feature_extractor
# Phase 2A: Custom CNN backbone → 38-class head
model_p2_cnn, backbone_cnn = build_phase2_from_backbone(model_cnn, model_name="phase2_custom_cnn")
print("Phase 2A — Custom CNN backbone:")
model_p2_cnn.summary()
# Phase 2B: MobileNetV2 backbone → 38-class head
model_p2_tl, backbone_tl = build_phase2_from_backbone(model_tl, model_name="phase2_mobilenet")
print("\nPhase 2B — MobileNetV2 backbone:")
model_p2_tl.summary()
# Verify frozen layers
for name, bb in [("CNN", backbone_cnn), ("MobileNet", backbone_tl)]:
n_trainable = sum(1 for layer in bb.layers if layer.trainable)
total = len(bb.layers)
print(f"\n{name} backbone: {n_trainable}/{total} trainable layers")Phase 2 batch images shape: (32, 52, 52, 3)
Phase 2 batch labels shape: (32,)
Sample labels: [ 6 12 28 27 24]
Phase 2A — Custom CNN backbone:2026-02-26 02:25:54.004939: I tensorflow/core/framework/local_rendezvous.cc:407] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequenceModel: "phase2_custom_cnn"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_image (InputLayer) │ (None, 52, 52, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ phase2_custom_cnn_backbone │ (None, 256) │ 390,336 │ │ (Functional) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 128) │ 32,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_2 (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ output_38 (Dense) │ (None, 38) │ 4,902 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 428,134 (1.63 MB)
Trainable params: 37,798 (147.65 KB)
Non-trainable params: 390,336 (1.49 MB)
Phase 2B — MobileNetV2 backbone:Model: "phase2_mobilenet"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_image (InputLayer) │ (None, 52, 52, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ phase2_mobilenet_backbone │ (None, 1280) │ 2,257,996 │ │ (Functional) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_3 (Dense) │ (None, 128) │ 163,968 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_3 (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ output_38 (Dense) │ (None, 38) │ 4,902 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 2,426,866 (9.26 MB)
Trainable params: 168,870 (659.65 KB)
Non-trainable params: 2,257,996 (8.61 MB)
CNN backbone: 0/18 trainable layers
MobileNet backbone: 0/5 trainable layersStep 11 — Phase 2 Training (Two-Stage)
Stage A: Train only the new head (backbone frozen), lr=1e-3, ~30 epochs Stage B: Unfreeze last 1-2 conv blocks, fine-tune end-to-end, lr=1e-5, ~30 epochs
Loss: sparse_categorical_crossentropy with class weights.
def train_phase2_two_stage(
model, backbone, train_ds, val_ds, class_weights, stage_a_epochs=30, stage_b_epochs=30, model_name="Phase2"
):
"""Two-stage Phase 2 training: head-only then fine-tune.
Stage A: Backbone frozen, train only the new head (lr=1e-3).
Stage B: Unfreeze last 2 conv blocks in backbone, fine-tune (lr=1e-5).
"""
# ── Stage A: Head-only training ──
separator = "=" * 60
print(f"\n{separator}")
print(f" {model_name} — Stage A: Head-only training")
print(separator)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
callbacks_a = [
tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.5, patience=5, min_lr=1e-6, verbose=1),
tf.keras.callbacks.EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True, verbose=1),
]
history_a = model.fit(
train_ds,
validation_data=val_ds,
epochs=stage_a_epochs,
callbacks=callbacks_a,
class_weight=class_weights,
verbose=1,
)
print(f"\n{separator}")
print(f"\n{'=' * 60}")
print(separator)
print(f"{'=' * 60}")
# Unfreeze last ~25% of backbone layers
backbone_layers = backbone.layers
unfreeze_from = int(len(backbone_layers) * 0.75)
for layer in backbone_layers[unfreeze_from:]:
if not isinstance(layer, layers.BatchNormalization):
layer.trainable = True
trainable_count = sum(1 for layer in backbone_layers if layer.trainable)
print(f" Unfroze layers from index {unfreeze_from}: {trainable_count}/{len(backbone_layers)} trainable")
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
callbacks_b = [
tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.5, patience=5, min_lr=1e-7, verbose=1),
tf.keras.callbacks.EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True, verbose=1),
]
history_b = model.fit(
train_ds,
validation_data=val_ds,
epochs=stage_b_epochs,
callbacks=callbacks_b,
class_weight=class_weights,
verbose=1,
)
return history_a, history_bTrain Phase 2A — Custom CNN Backbone
hist_p2_cnn_a, hist_p2_cnn_b = train_phase2_two_stage(
model_p2_cnn,
backbone_cnn,
train_ds_p2,
val_ds_p2,
class_weights_dict,
model_name="Phase2 Custom CNN",
)============================================================ Phase2 Custom CNN — Stage A: Head-only training ============================================================ Epoch 1/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 9s 10ms/step - accuracy: 0.6489 - loss: 1.1442 - val_accuracy: 0.9318 - val_loss: 0.2510 - learning_rate: 0.0010 Epoch 2/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step - accuracy: 0.8913 - loss: 0.3612 - val_accuracy: 0.9558 - val_loss: 0.1583 - learning_rate: 0.0010 Epoch 3/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step - accuracy: 0.9196 - loss: 0.2634 - val_accuracy: 0.9611 - val_loss: 0.1393 - learning_rate: 0.0010 Epoch 4/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9318 - loss: 0.2301 - val_accuracy: 0.9616 - val_loss: 0.1260 - learning_rate: 0.0010 Epoch 5/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9386 - loss: 0.2087 - val_accuracy: 0.9637 - val_loss: 0.1261 - learning_rate: 0.0010 Epoch 6/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9410 - loss: 0.1934 - val_accuracy: 0.9633 - val_loss: 0.1255 - learning_rate: 0.0010 Epoch 7/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step - accuracy: 0.9447 - loss: 0.1866 - val_accuracy: 0.9655 - val_loss: 0.1242 - learning_rate: 0.0010 Epoch 8/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9463 - loss: 0.1783 - val_accuracy: 0.9625 - val_loss: 0.1398 - learning_rate: 0.0010 Epoch 9/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9469 - loss: 0.1746 - val_accuracy: 0.9647 - val_loss: 0.1267 - learning_rate: 0.0010 Epoch 10/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9483 - loss: 0.1687 - val_accuracy: 0.9653 - val_loss: 0.1292 - learning_rate: 0.0010 Epoch 11/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9548 - loss: 0.1603 - val_accuracy: 0.9676 - val_loss: 0.1259 - learning_rate: 0.0010 Epoch 12/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9528 - loss: 0.1614 - val_accuracy: 0.9670 - val_loss: 0.1197 - learning_rate: 0.0010 Epoch 13/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step - accuracy: 0.9540 - loss: 0.1613 - val_accuracy: 0.9686 - val_loss: 0.1325 - learning_rate: 0.0010 Epoch 14/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9528 - loss: 0.1564 - val_accuracy: 0.9660 - val_loss: 0.1319 - learning_rate: 0.0010 Epoch 15/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9525 - loss: 0.1565 - val_accuracy: 0.9670 - val_loss: 0.1335 - learning_rate: 0.0010 Epoch 16/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9550 - loss: 0.1549 - val_accuracy: 0.9656 - val_loss: 0.1385 - learning_rate: 0.0010 Epoch 17/30 830/832 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9524 - loss: 0.1560 Epoch 17: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257. 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9542 - loss: 0.1498 - val_accuracy: 0.9662 - val_loss: 0.1284 - learning_rate: 0.0010 Epoch 18/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9596 - loss: 0.1377 - val_accuracy: 0.9700 - val_loss: 0.1210 - learning_rate: 5.0000e-04 Epoch 19/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 8s 9ms/step - accuracy: 0.9615 - loss: 0.1330 - val_accuracy: 0.9681 - val_loss: 0.1303 - learning_rate: 5.0000e-04 Epoch 20/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9625 - loss: 0.1325 - val_accuracy: 0.9693 - val_loss: 0.1244 - learning_rate: 5.0000e-04 Epoch 21/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9626 - loss: 0.1310 - val_accuracy: 0.9698 - val_loss: 0.1218 - learning_rate: 5.0000e-04 Epoch 22/30 829/832 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9616 - loss: 0.1321 Epoch 22: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628. 832/832 ━━━━━━━━━━━━━━━━━━━━ 7s 9ms/step - accuracy: 0.9619 - loss: 0.1341 - val_accuracy: 0.9704 - val_loss: 0.1225 - learning_rate: 5.0000e-04 Epoch 22: early stopping Restoring model weights from the end of the best epoch: 12. ============================================================ ============================================================ ============================================================ ============================================================ Unfroze layers from index 13: 4/18 trainable Epoch 1/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 11s 12ms/step - accuracy: 0.9565 - loss: 0.1454 - val_accuracy: 0.9683 - val_loss: 0.1171 - learning_rate: 1.0000e-05 Epoch 2/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9580 - loss: 0.1353 - val_accuracy: 0.9695 - val_loss: 0.1138 - learning_rate: 1.0000e-05 Epoch 3/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9598 - loss: 0.1360 - val_accuracy: 0.9705 - val_loss: 0.1133 - learning_rate: 1.0000e-05 Epoch 4/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9607 - loss: 0.1339 - val_accuracy: 0.9702 - val_loss: 0.1139 - learning_rate: 1.0000e-05 Epoch 5/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9624 - loss: 0.1353 - val_accuracy: 0.9705 - val_loss: 0.1116 - learning_rate: 1.0000e-05 Epoch 6/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9635 - loss: 0.1271 - val_accuracy: 0.9700 - val_loss: 0.1127 - learning_rate: 1.0000e-05 Epoch 7/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9643 - loss: 0.1265 - val_accuracy: 0.9712 - val_loss: 0.1112 - learning_rate: 1.0000e-05 Epoch 8/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9639 - loss: 0.1257 - val_accuracy: 0.9723 - val_loss: 0.1095 - learning_rate: 1.0000e-05 Epoch 9/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9643 - loss: 0.1276 - val_accuracy: 0.9721 - val_loss: 0.1101 - learning_rate: 1.0000e-05 Epoch 10/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9622 - loss: 0.1294 - val_accuracy: 0.9721 - val_loss: 0.1098 - learning_rate: 1.0000e-05 Epoch 11/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9646 - loss: 0.1252 - val_accuracy: 0.9721 - val_loss: 0.1097 - learning_rate: 1.0000e-05 Epoch 12/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9629 - loss: 0.1274 - val_accuracy: 0.9716 - val_loss: 0.1080 - learning_rate: 1.0000e-05 Epoch 13/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9658 - loss: 0.1192 - val_accuracy: 0.9725 - val_loss: 0.1093 - learning_rate: 1.0000e-05 Epoch 14/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9658 - loss: 0.1251 - val_accuracy: 0.9719 - val_loss: 0.1097 - learning_rate: 1.0000e-05 Epoch 15/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9652 - loss: 0.1249 - val_accuracy: 0.9719 - val_loss: 0.1089 - learning_rate: 1.0000e-05 Epoch 16/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9649 - loss: 0.1217 - val_accuracy: 0.9719 - val_loss: 0.1083 - learning_rate: 1.0000e-05 Epoch 17/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 10ms/step - accuracy: 0.9653 - loss: 0.1246 Epoch 17: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-06. 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9646 - loss: 0.1243 - val_accuracy: 0.9716 - val_loss: 0.1091 - learning_rate: 1.0000e-05 Epoch 18/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9651 - loss: 0.1230 - val_accuracy: 0.9721 - val_loss: 0.1083 - learning_rate: 5.0000e-06 Epoch 19/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9678 - loss: 0.1214 - val_accuracy: 0.9721 - val_loss: 0.1080 - learning_rate: 5.0000e-06 Epoch 20/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9672 - loss: 0.1194 - val_accuracy: 0.9723 - val_loss: 0.1085 - learning_rate: 5.0000e-06 Epoch 21/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9650 - loss: 0.1216 - val_accuracy: 0.9723 - val_loss: 0.1084 - learning_rate: 5.0000e-06 Epoch 22/30 827/832 ━━━━━━━━━━━━━━━━━━━━ 0s 10ms/step - accuracy: 0.9652 - loss: 0.1215 Epoch 22: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-06. 832/832 ━━━━━━━━━━━━━━━━━━━━ 10s 12ms/step - accuracy: 0.9662 - loss: 0.1177 - val_accuracy: 0.9726 - val_loss: 0.1082 - learning_rate: 5.0000e-06 Epoch 22: early stopping Restoring model weights from the end of the best epoch: 12.
Train Phase 2B — MobileNetV2 Backbone
hist_p2_tl_a, hist_p2_tl_b = train_phase2_two_stage(
model_p2_tl,
backbone_tl,
train_ds_p2,
val_ds_p2,
class_weights_dict,
model_name="Phase2 MobileNetV2",
)============================================================ Phase2 MobileNetV2 — Stage A: Head-only training ============================================================ Epoch 1/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 99s 115ms/step - accuracy: 0.2201 - loss: 2.4609 - val_accuracy: 0.4660 - val_loss: 1.6635 - learning_rate: 0.0010 Epoch 2/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.3773 - loss: 1.7501 - val_accuracy: 0.5558 - val_loss: 1.3109 - learning_rate: 0.0010 Epoch 3/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.4292 - loss: 1.5843 - val_accuracy: 0.5680 - val_loss: 1.2359 - learning_rate: 0.0010 Epoch 4/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.4573 - loss: 1.4787 - val_accuracy: 0.5896 - val_loss: 1.1411 - learning_rate: 0.0010 Epoch 5/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.4760 - loss: 1.4259 - val_accuracy: 0.6001 - val_loss: 1.1324 - learning_rate: 0.0010 Epoch 6/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.4892 - loss: 1.3843 - val_accuracy: 0.6093 - val_loss: 1.0835 - learning_rate: 0.0010 Epoch 7/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.4985 - loss: 1.3570 - val_accuracy: 0.6114 - val_loss: 1.0606 - learning_rate: 0.0010 Epoch 8/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 115ms/step - accuracy: 0.5113 - loss: 1.3226 - val_accuracy: 0.6142 - val_loss: 1.0373 - learning_rate: 0.0010 Epoch 9/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5134 - loss: 1.3194 - val_accuracy: 0.6363 - val_loss: 1.0381 - learning_rate: 0.0010 Epoch 10/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5212 - loss: 1.2836 - val_accuracy: 0.6506 - val_loss: 0.9742 - learning_rate: 0.0010 Epoch 11/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5246 - loss: 1.2738 - val_accuracy: 0.6312 - val_loss: 1.0046 - learning_rate: 0.0010 Epoch 12/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 114ms/step - accuracy: 0.5305 - loss: 1.2639 - val_accuracy: 0.6478 - val_loss: 0.9646 - learning_rate: 0.0010 Epoch 13/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5356 - loss: 1.2431 - val_accuracy: 0.6452 - val_loss: 0.9677 - learning_rate: 0.0010 Epoch 14/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5372 - loss: 1.2391 - val_accuracy: 0.6512 - val_loss: 0.9617 - learning_rate: 0.0010 Epoch 15/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5381 - loss: 1.2335 - val_accuracy: 0.6445 - val_loss: 0.9929 - learning_rate: 0.0010 Epoch 16/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5478 - loss: 1.2089 - val_accuracy: 0.6626 - val_loss: 0.9524 - learning_rate: 0.0010 Epoch 17/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5483 - loss: 1.2176 - val_accuracy: 0.6640 - val_loss: 0.9187 - learning_rate: 0.0010 Epoch 18/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5484 - loss: 1.2098 - val_accuracy: 0.6661 - val_loss: 0.9082 - learning_rate: 0.0010 Epoch 19/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5531 - loss: 1.2042 - val_accuracy: 0.6575 - val_loss: 0.9296 - learning_rate: 0.0010 Epoch 20/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5555 - loss: 1.1974 - val_accuracy: 0.6596 - val_loss: 0.9247 - learning_rate: 0.0010 Epoch 21/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5581 - loss: 1.1962 - val_accuracy: 0.6410 - val_loss: 0.9619 - learning_rate: 0.0010 Epoch 22/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5613 - loss: 1.1805 - val_accuracy: 0.6663 - val_loss: 0.9199 - learning_rate: 0.0010 Epoch 23/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 0s 93ms/step - accuracy: 0.5605 - loss: 1.1922 Epoch 23: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257. 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5535 - loss: 1.1934 - val_accuracy: 0.6578 - val_loss: 0.9575 - learning_rate: 0.0010 Epoch 24/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5810 - loss: 1.1299 - val_accuracy: 0.6791 - val_loss: 0.8745 - learning_rate: 5.0000e-04 Epoch 25/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5842 - loss: 1.1182 - val_accuracy: 0.6864 - val_loss: 0.8703 - learning_rate: 5.0000e-04 Epoch 26/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5908 - loss: 1.1094 - val_accuracy: 0.6926 - val_loss: 0.8568 - learning_rate: 5.0000e-04 Epoch 27/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 95s 114ms/step - accuracy: 0.5904 - loss: 1.1006 - val_accuracy: 0.6878 - val_loss: 0.8455 - learning_rate: 5.0000e-04 Epoch 28/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5914 - loss: 1.1067 - val_accuracy: 0.6848 - val_loss: 0.8505 - learning_rate: 5.0000e-04 Epoch 29/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5959 - loss: 1.1009 - val_accuracy: 0.6787 - val_loss: 0.8737 - learning_rate: 5.0000e-04 Epoch 30/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 94s 113ms/step - accuracy: 0.5910 - loss: 1.0997 - val_accuracy: 0.6829 - val_loss: 0.8633 - learning_rate: 5.0000e-04 Restoring model weights from the end of the best epoch: 27. ============================================================ ============================================================ ============================================================ ============================================================ Unfroze layers from index 3: 2/5 trainable Epoch 1/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 530s 619ms/step - accuracy: 0.2226 - loss: 8.0492 - val_accuracy: 0.0659 - val_loss: 33.8210 - learning_rate: 1.0000e-05 Epoch 2/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 514s 618ms/step - accuracy: 0.3278 - loss: 1.9544 - val_accuracy: 0.0680 - val_loss: 23.8821 - learning_rate: 1.0000e-05 Epoch 3/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 521s 626ms/step - accuracy: 0.4084 - loss: 1.6009 - val_accuracy: 0.0944 - val_loss: 15.0651 - learning_rate: 1.0000e-05 Epoch 4/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.4989 - loss: 1.3403 - val_accuracy: 0.4863 - val_loss: 1.5419 - learning_rate: 1.0000e-05 Epoch 5/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 517s 621ms/step - accuracy: 0.5785 - loss: 1.1375 - val_accuracy: 0.6794 - val_loss: 0.8602 - learning_rate: 1.0000e-05 Epoch 6/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.6296 - loss: 0.9978 - val_accuracy: 0.7238 - val_loss: 0.7043 - learning_rate: 1.0000e-05 Epoch 7/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 512s 615ms/step - accuracy: 0.6718 - loss: 0.8882 - val_accuracy: 0.7811 - val_loss: 0.5720 - learning_rate: 1.0000e-05 Epoch 8/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.7015 - loss: 0.8086 - val_accuracy: 0.8057 - val_loss: 0.5145 - learning_rate: 1.0000e-05 Epoch 9/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 618ms/step - accuracy: 0.7303 - loss: 0.7397 - val_accuracy: 0.8390 - val_loss: 0.4451 - learning_rate: 1.0000e-05 Epoch 10/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.7483 - loss: 0.6877 - val_accuracy: 0.8576 - val_loss: 0.3895 - learning_rate: 1.0000e-05 Epoch 11/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 512s 616ms/step - accuracy: 0.7668 - loss: 0.6391 - val_accuracy: 0.8788 - val_loss: 0.3511 - learning_rate: 1.0000e-05 Epoch 12/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 511s 614ms/step - accuracy: 0.7868 - loss: 0.5932 - val_accuracy: 0.9046 - val_loss: 0.2964 - learning_rate: 1.0000e-05 Epoch 13/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 616ms/step - accuracy: 0.8002 - loss: 0.5562 - val_accuracy: 0.9060 - val_loss: 0.2848 - learning_rate: 1.0000e-05 Epoch 14/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 517s 621ms/step - accuracy: 0.8107 - loss: 0.5324 - val_accuracy: 0.9158 - val_loss: 0.2634 - learning_rate: 1.0000e-05 Epoch 15/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 514s 618ms/step - accuracy: 0.8114 - loss: 0.5225 - val_accuracy: 0.9265 - val_loss: 0.2450 - learning_rate: 1.0000e-05 Epoch 16/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 514s 618ms/step - accuracy: 0.8254 - loss: 0.4827 - val_accuracy: 0.9342 - val_loss: 0.2189 - learning_rate: 1.0000e-05 Epoch 17/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 619ms/step - accuracy: 0.8370 - loss: 0.4582 - val_accuracy: 0.9398 - val_loss: 0.2004 - learning_rate: 1.0000e-05 Epoch 18/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 619ms/step - accuracy: 0.8403 - loss: 0.4523 - val_accuracy: 0.9460 - val_loss: 0.1828 - learning_rate: 1.0000e-05 Epoch 19/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.8419 - loss: 0.4457 - val_accuracy: 0.9511 - val_loss: 0.1792 - learning_rate: 1.0000e-05 Epoch 20/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 616ms/step - accuracy: 0.8500 - loss: 0.4260 - val_accuracy: 0.9519 - val_loss: 0.1700 - learning_rate: 1.0000e-05 Epoch 21/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 619ms/step - accuracy: 0.8554 - loss: 0.4157 - val_accuracy: 0.9498 - val_loss: 0.1735 - learning_rate: 1.0000e-05 Epoch 22/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 617ms/step - accuracy: 0.8610 - loss: 0.3910 - val_accuracy: 0.9516 - val_loss: 0.1638 - learning_rate: 1.0000e-05 Epoch 23/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 511s 614ms/step - accuracy: 0.8627 - loss: 0.3956 - val_accuracy: 0.9569 - val_loss: 0.1535 - learning_rate: 1.0000e-05 Epoch 24/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 516s 620ms/step - accuracy: 0.8655 - loss: 0.3892 - val_accuracy: 0.9532 - val_loss: 0.1572 - learning_rate: 1.0000e-05 Epoch 25/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 619ms/step - accuracy: 0.8717 - loss: 0.3680 - val_accuracy: 0.9579 - val_loss: 0.1503 - learning_rate: 1.0000e-05 Epoch 26/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 616ms/step - accuracy: 0.8763 - loss: 0.3616 - val_accuracy: 0.9591 - val_loss: 0.1459 - learning_rate: 1.0000e-05 Epoch 27/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 512s 616ms/step - accuracy: 0.8776 - loss: 0.3544 - val_accuracy: 0.9586 - val_loss: 0.1474 - learning_rate: 1.0000e-05 Epoch 28/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 514s 617ms/step - accuracy: 0.8826 - loss: 0.3386 - val_accuracy: 0.9609 - val_loss: 0.1369 - learning_rate: 1.0000e-05 Epoch 29/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 513s 616ms/step - accuracy: 0.8876 - loss: 0.3253 - val_accuracy: 0.9628 - val_loss: 0.1325 - learning_rate: 1.0000e-05 Epoch 30/30 832/832 ━━━━━━━━━━━━━━━━━━━━ 515s 619ms/step - accuracy: 0.8873 - loss: 0.3217 - val_accuracy: 0.9632 - val_loss: 0.1285 - learning_rate: 1.0000e-05 Restoring model weights from the end of the best epoch: 30.
Save models
Step 12 — Phase 2 Evaluation & Final Comparison
Evaluate both Phase 2 models on the test set with per-class F1 scores, grouped by defect count (single, double, triple, quadruple). Then produce a final summary table comparing all 4 models.
from sklearn.metrics import confusion_matrix
# All 38 pattern names in class ID order
all_pattern_names = [id_to_pattern[i] for i in range(NUM_CLASSES)]
def evaluate_phase2(model, dataset, y_true, model_name):
"""Evaluate a 38-class Phase 2 model with per-class and grouped metrics."""
y_pred = model.predict(dataset, verbose=0).argmax(axis=1)
separator = "=" * 60
print(f"\n{separator}")
print(f" {model_name} — Test Set Results (38 classes)")
print(separator)
report = classification_report(
y_true,
y_pred,
target_names=all_pattern_names,
zero_division=0,
output_dict=True,
)
print(
classification_report(
y_true,
y_pred,
target_names=all_pattern_names,
zero_division=0,
)
)
macro_f1 = f1_score(y_true, y_pred, average="macro", zero_division=0)
weighted_f1 = f1_score(y_true, y_pred, average="weighted", zero_division=0)
accuracy = np.mean(y_pred == y_true)
print(f"Accuracy: {accuracy:.4f}")
print(f"Macro F1: {macro_f1:.4f}")
print(f"Weighted F1: {weighted_f1:.4f}")
print("\nF1 by defect combination count:")
for n_plus in range(4):
group_labels = [name for name in all_pattern_names if name.count("+") == n_plus]
group_f1s = [report[name]["f1-score"] for name in group_labels if name in report]
if group_f1s:
group_name = ["Single/Normal", "Double", "Triple", "Quadruple"][n_plus]
print(f" {group_name:<12} avg F1={np.mean(group_f1s):.4f} (n={len(group_f1s)} classes)")
return y_pred, report, macro_f1, weighted_f1
y_pred_p2_cnn, report_p2_cnn, mf1_p2_cnn, wf1_p2_cnn = evaluate_phase2(
model_p2_cnn,
test_ds_p2,
y_class_test,
"Phase2 Custom CNN",
)
y_pred_p2_tl, report_p2_tl, mf1_p2_tl, wf1_p2_tl = evaluate_phase2(
model_p2_tl,
test_ds_p2,
y_class_test,
"Phase2 MobileNetV2",
)
============================================================
Phase2 Custom CNN — Test Set Results (38 classes)
============================================================
precision recall f1-score support
Normal 1.00 1.00 1.00 150
Random 1.00 0.99 1.00 130
Scratch 0.99 1.00 0.99 150
Near_Full 0.96 1.00 0.98 23
Loc 0.96 1.00 0.98 150
Loc+Scratch 1.00 0.95 0.98 150
Edge_Ring 0.98 0.99 0.98 150
Edge_Ring+Scratch 0.99 0.97 0.98 150
Edge_Ring+Loc 0.92 0.97 0.94 150
Edge_Ring+Loc+Scratch 0.97 0.91 0.94 150
Edge_Loc 0.99 0.98 0.98 150
Edge_Loc+Scratch 0.97 0.99 0.98 150
Edge_Loc+Loc 0.96 0.99 0.97 150
Edge_Loc+Loc+Scratch 0.99 0.95 0.97 150
Donut 0.95 0.99 0.97 150
Donut+Scratch 0.97 0.98 0.98 150
Donut+Loc 0.94 0.95 0.95 150
Donut+Loc+Scratch 0.97 0.94 0.96 150
Donut+Edge_Ring 0.97 0.98 0.98 150
Donut+Edge_Ring+Scratch 0.95 0.97 0.96 150
Donut+Edge_Ring+Loc 0.98 0.99 0.99 150
Donut+Edge_Ring+Loc+Scratch 0.99 0.97 0.98 150
Donut+Edge_Loc 0.98 0.93 0.96 150
Donut+Edge_Loc+Scratch 0.94 0.95 0.95 150
Donut+Edge_Loc+Loc 1.00 0.96 0.98 150
Donut+Edge_Loc+Loc+Scratch 0.97 0.99 0.98 150
Center 1.00 0.99 1.00 150
Center+Scratch 0.96 1.00 0.98 150
Center+Loc 0.97 0.99 0.98 150
Center+Loc+Scratch 0.99 0.97 0.98 150
Center+Edge_Ring 0.98 0.99 0.99 150
Center+Edge_Ring+Scratch 0.97 0.97 0.97 150
Center+Edge_Ring+Loc 0.94 0.98 0.96 150
Center+Edge_Ring+Loc+Scratch 0.97 0.95 0.96 150
Center+Edge_Loc 0.99 0.99 0.99 150
Center+Edge_Loc+Scratch 1.00 0.96 0.98 300
Center+Edge_Loc+Loc 0.95 0.98 0.96 150
Center+Edge_Loc+Loc+Scratch 0.99 0.95 0.97 150
accuracy 0.97 5703
macro avg 0.97 0.97 0.97 5703
weighted avg 0.97 0.97 0.97 5703
Accuracy: 0.9735
Macro F1: 0.9736
Weighted F1: 0.9735
F1 by defect combination count:
Single/Normal avg F1=0.9866 (n=9 classes)
Double avg F1=0.9725 (n=13 classes)
Triple avg F1=0.9655 (n=12 classes)
Quadruple avg F1=0.9722 (n=4 classes)
============================================================
Phase2 MobileNetV2 — Test Set Results (38 classes)
============================================================
precision recall f1-score support
Normal 1.00 1.00 1.00 150
Random 1.00 0.99 1.00 130
Scratch 0.95 1.00 0.97 150
Near_Full 0.96 1.00 0.98 23
Loc 0.96 0.99 0.97 150
Loc+Scratch 0.97 0.95 0.96 150
Edge_Ring 0.96 1.00 0.98 150
Edge_Ring+Scratch 0.94 1.00 0.97 150
Edge_Ring+Loc 0.92 0.97 0.95 150
Edge_Ring+Loc+Scratch 0.94 0.90 0.92 150
Edge_Loc 0.99 0.97 0.98 150
Edge_Loc+Scratch 1.00 0.92 0.96 150
Edge_Loc+Loc 0.97 0.99 0.98 150
Edge_Loc+Loc+Scratch 1.00 0.89 0.94 150
Donut 0.96 1.00 0.98 150
Donut+Scratch 0.96 0.99 0.98 150
Donut+Loc 0.97 0.98 0.97 150
Donut+Loc+Scratch 0.95 0.97 0.96 150
Donut+Edge_Ring 0.96 1.00 0.98 150
Donut+Edge_Ring+Scratch 0.91 0.99 0.95 150
Donut+Edge_Ring+Loc 0.96 1.00 0.98 150
Donut+Edge_Ring+Loc+Scratch 0.97 0.96 0.96 150
Donut+Edge_Loc 0.97 0.95 0.96 150
Donut+Edge_Loc+Scratch 0.99 0.87 0.93 150
Donut+Edge_Loc+Loc 1.00 0.96 0.98 150
Donut+Edge_Loc+Loc+Scratch 0.99 0.91 0.95 150
Center 1.00 0.99 1.00 150
Center+Scratch 0.93 1.00 0.96 150
Center+Loc 0.96 1.00 0.98 150
Center+Loc+Scratch 0.98 0.97 0.98 150
Center+Edge_Ring 0.96 1.00 0.98 150
Center+Edge_Ring+Scratch 0.89 0.99 0.94 150
Center+Edge_Ring+Loc 0.93 0.99 0.96 150
Center+Edge_Ring+Loc+Scratch 0.98 0.97 0.98 150
Center+Edge_Loc 0.99 0.96 0.97 150
Center+Edge_Loc+Scratch 0.99 0.91 0.95 300
Center+Edge_Loc+Loc 0.97 0.92 0.95 150
Center+Edge_Loc+Loc+Scratch 1.00 0.92 0.96 150
accuracy 0.97 5703
macro avg 0.97 0.97 0.97 5703
weighted avg 0.97 0.97 0.97 5703
Accuracy: 0.9660
Macro F1: 0.9667
Weighted F1: 0.9658
F1 by defect combination count:
Single/Normal avg F1=0.9841 (n=9 classes)
Double avg F1=0.9690 (n=13 classes)
Triple avg F1=0.9527 (n=12 classes)
Quadruple avg F1=0.9624 (n=4 classes)# Confusion matrix for the best Phase 2 model
best_p2_name = "Custom CNN" if mf1_p2_cnn >= mf1_p2_tl else "MobileNetV2"
best_p2_pred = y_pred_p2_cnn if mf1_p2_cnn >= mf1_p2_tl else y_pred_p2_tl
print(f"Plotting confusion matrix for best Phase 2 model: {best_p2_name}")
cm = confusion_matrix(y_class_test, best_p2_pred, labels=np.arange(NUM_CLASSES))
# Convert to percentages (normalize by row)
cm_percent = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis] * 100
fig, ax = plt.subplots(figsize=(20, 18))
sns.heatmap(
cm_percent,
annot=True,
fmt=".1f",
cmap="Blues",
xticklabels=all_pattern_names,
yticklabels=all_pattern_names,
ax=ax,
linewidths=0.5,
cbar_kws={"label": "Percentage (%)"},
)
ax.set_xlabel("Predicted", fontsize=12)
ax.set_ylabel("True", fontsize=12)
ax.set_title(f"Phase 2 — {best_p2_name} Confusion Matrix (38 classes, %)", fontsize=14)
plt.xticks(rotation=90, fontsize=7)
plt.yticks(rotation=0, fontsize=7)
plt.tight_layout()
plt.show()
# Confusion matrices split by defect-combination count for the best Phase 2 model
best_p2_name = "Custom CNN" if mf1_p2_cnn >= mf1_p2_tl else "MobileNetV2"
best_p2_pred = y_pred_p2_cnn if mf1_p2_cnn >= mf1_p2_tl else y_pred_p2_tl
print(f"Plotting split confusion matrices for best Phase 2 model: {best_p2_name}")
group_defect_counts = {
"Base patterns (single/normal)": 0,
"Two-defect combinations": 1,
"Three-defect combinations": 2,
"Four-defect combinations": 3,
}
def plot_group_confusion_matrix(group_name, plus_count):
"""Plot confusion matrix for classes with a specific '+' count in the label name."""
group_ids = [cid for cid, name in id_to_pattern.items() if name.count("+") == plus_count]
group_names = [id_to_pattern[cid] for cid in group_ids]
# Use only samples whose true class is in this group
mask = np.isin(y_class_test, group_ids)
y_true_group = y_class_test[mask]
y_pred_group = best_p2_pred[mask]
cm = confusion_matrix(y_true_group, y_pred_group, labels=group_ids)
row_sums = cm.sum(axis=1, keepdims=True)
cm_percent = np.divide(cm, row_sums, out=np.zeros_like(cm, dtype=float), where=row_sums != 0) * 100
fig_w = max(8, 0.6 * len(group_names))
fig_h = max(6, 0.6 * len(group_names))
fig, ax = plt.subplots(figsize=(fig_w, fig_h)) # noqa: RUF059
sns.heatmap(
cm_percent,
annot=True,
fmt=".1f",
cmap="Blues",
xticklabels=group_names,
yticklabels=group_names,
ax=ax,
linewidths=0.5,
cbar_kws={"label": "Percentage (%)"},
)
ax.set_xlabel("Predicted", fontsize=11)
ax.set_ylabel("True", fontsize=11)
ax.set_title(f"Phase 2 — {best_p2_name} Confusion Matrix ({group_name}, %)", fontsize=13)
plt.xticks(rotation=90, fontsize=7)
plt.yticks(rotation=0, fontsize=7)
plt.tight_layout()
plt.show()
for group_name, plus_count in group_defect_counts.items():
plot_group_confusion_matrix(group_name, plus_count)Plotting confusion matrix for best Phase 2 model: Custom CNN
Plotting split confusion matrices for best Phase 2 model: Custom CNN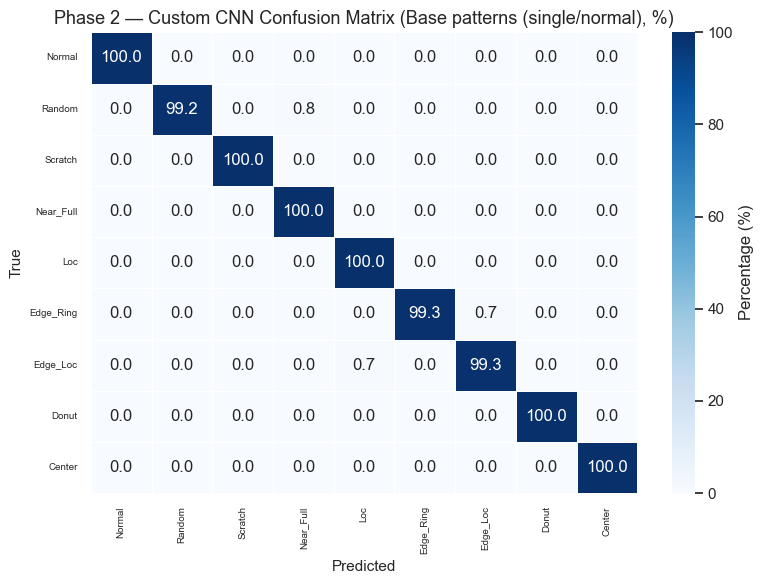
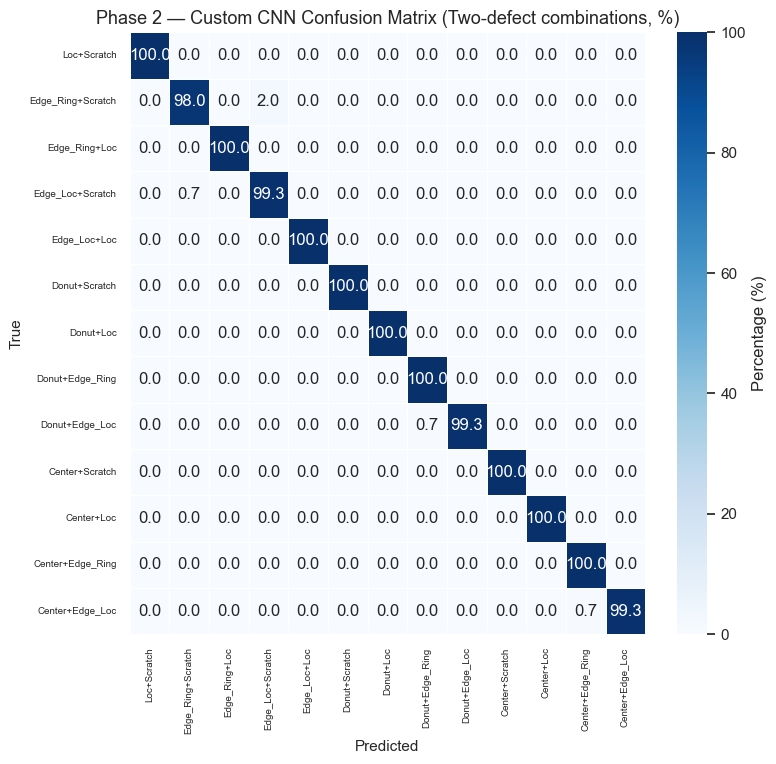
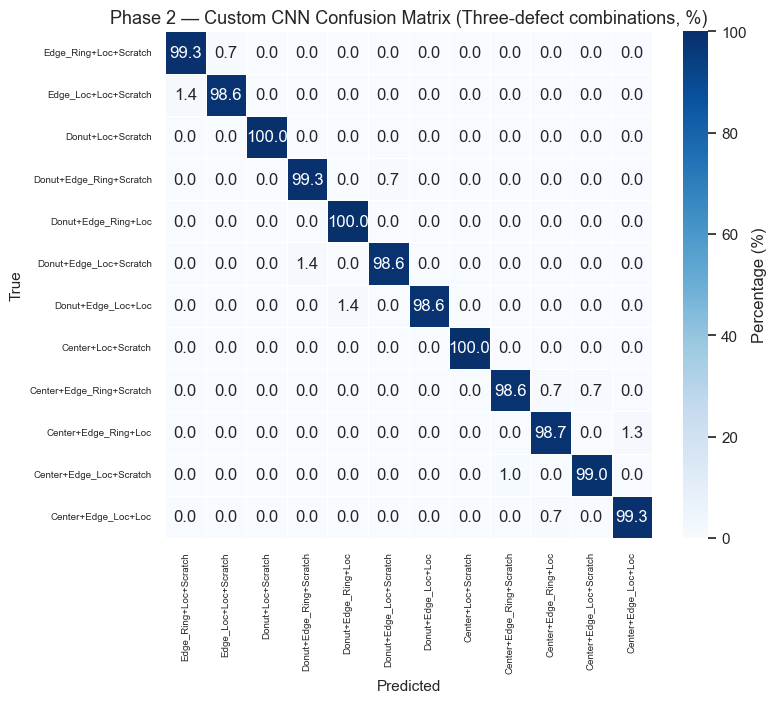
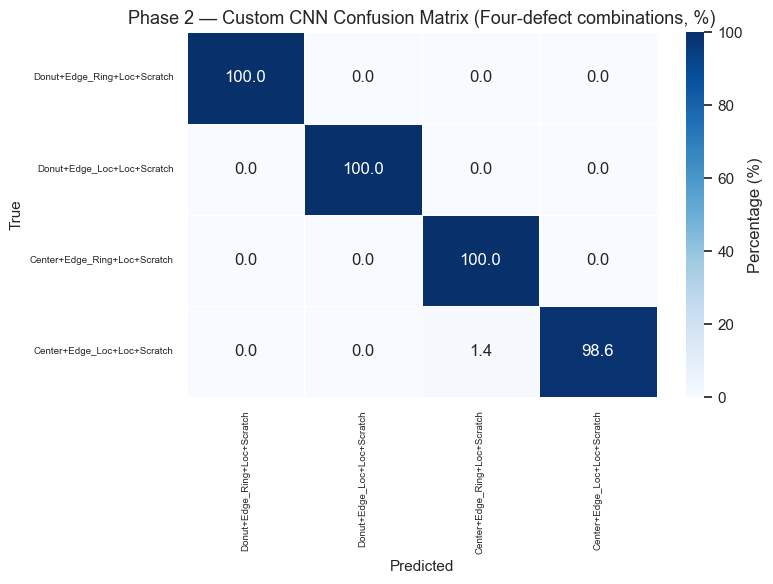
# ── Final Summary Table: All 4 Models ──
summary_data = {
"Model": [
"Phase 1 — Custom CNN (8-label)",
"Phase 1 — MobileNetV2 (8-label)",
"Phase 2 — Custom CNN (38-class)",
"Phase 2 — MobileNetV2 (38-class)",
],
"Macro F1": [
report_cnn["macro avg"]["f1-score"],
report_tl["macro avg"]["f1-score"],
mf1_p2_cnn,
mf1_p2_tl,
],
"Weighted F1": [
report_cnn["weighted avg"]["f1-score"],
report_tl["weighted avg"]["f1-score"],
wf1_p2_cnn,
wf1_p2_tl,
],
}
summary_df = pd.DataFrame(summary_data)
display(
summary_df.style
.format({"Macro F1": "{:.4f}", "Weighted F1": "{:.4f}"})
.highlight_max(subset=["Macro F1", "Weighted F1"], color="lightgreen")
.set_caption("Final Model Comparison — All Phases")
)| Model | Macro F1 | Weighted F1 | |
|---|---|---|---|
| 0 | Phase 1 — Custom CNN (8-label) | 0.9779 | 0.9905 |
| 1 | Phase 1 — MobileNetV2 (8-label) | 0.8998 | 0.8847 |
| 2 | Phase 2 — Custom CNN (38-class) | 0.9736 | 0.9735 |
| 3 | Phase 2 — MobileNetV2 (38-class) | 0.9667 | 0.9658 |
Save models
# Create a directory for Phase 2 models
MODELS_DIR = "phase2_models"
os.makedirs(MODELS_DIR, exist_ok=True)
# Save Phase 2 models
model_p2_cnn.save(f"{MODELS_DIR}/model_p2_cnn.keras")
model_p2_tl.save(f"{MODELS_DIR}/model_p2_tl.keras")
print(f"✓ Phase 2 models saved to '{MODELS_DIR}/':")
print(" - model_p2_cnn.keras")
print(" - model_p2_tl.keras")✓ Phase 2 models saved to 'phase2_models/':
- model_p2_cnn.keras
- model_p2_tl.kerasSave Training Artifacts
# Create a directory for artifacts
ARTIFACT_DIR = "training_artifacts"
os.makedirs(ARTIFACT_DIR, exist_ok=True)
# Save all trained models
model_cnn.save(f"{ARTIFACT_DIR}/model_cnn.keras")
model_tl.save(f"{ARTIFACT_DIR}/model_tl.keras")
model_p2_cnn.save(f"{ARTIFACT_DIR}/model_p2_cnn.keras")
model_p2_tl.save(f"{ARTIFACT_DIR}/model_p2_tl.keras")
# Make a copy if running all notebooks sequentially to avoid overwriting
model_cnn2 = model_cnn
model_tl2 = model_tl
model_p2_cnn2 = model_p2_cnn
model_p2_tl2 = model_p2_tl
# Save everything else in pickle (keep original types)
artifacts = {
"X_train": X_train,
"X_val": X_val,
"X_test": X_test,
"y_train": y_train,
"y_val": y_val,
"y_test": y_test,
"y_class_train": y_class_train,
"y_class_val": y_class_val,
"y_class_test": y_class_test,
"label_mapping": label_mapping,
"pattern_to_id": pattern_to_id,
"id_to_pattern": id_to_pattern,
"class_weights_dict": class_weights_dict,
"pos_weights_tensor": pos_weights_tensor,
"history_cnn": history_cnn,
"history_tl": history_tl,
"hist_p2_cnn_a": hist_p2_cnn_a,
"hist_p2_cnn_b": hist_p2_cnn_b,
"hist_p2_tl_a": hist_p2_tl_a,
"hist_p2_tl_b": hist_p2_tl_b,
"BinaryFocalLoss": BinaryFocalLoss,
"focal_loss": focal_loss,
"THRESHOLD": THRESHOLD,
"NUM_CLASSES": NUM_CLASSES,
"BATCH_SIZE": BATCH_SIZE,
"EPOCHS": EPOCHS,
"TARGET_SIZE": TARGET_SIZE,
"AUTOTUNE": AUTOTUNE,
}
with open(f"{ARTIFACT_DIR}/artifacts.pkl", "wb") as f:
pickle.dump(artifacts, f)
print(f"\n✓ All artifacts saved to '{ARTIFACT_DIR}/':")
print(" - model_cnn.keras")
print(" - model_tl.keras")
print(" - model_p2_cnn.keras")
print(" - model_p2_tl.keras")
print(" - artifacts.pkl")
✓ All artifacts saved to 'training_artifacts/':
- model_cnn.keras
- model_tl.keras
- model_p2_cnn.keras
- model_p2_tl.keras
- artifacts.pklLoad Training Artifacts
ARTIFACT_DIR = "training_artifacts"
# Load all models
print("Loading models...")
model_cnn = tf.keras.models.load_model(f"{ARTIFACT_DIR}/model_cnn.keras")
model_tl = tf.keras.models.load_model(f"{ARTIFACT_DIR}/model_tl.keras")
model_p2_cnn = tf.keras.models.load_model(f"{ARTIFACT_DIR}/model_p2_cnn.keras")
model_p2_tl = tf.keras.models.load_model(f"{ARTIFACT_DIR}/model_p2_tl.keras")
print("✓ All models loaded")
# Load all artifacts
print("Loading artifacts...")
with open(f"{ARTIFACT_DIR}/artifacts.pkl", "rb") as f:
artifacts = pickle.load(f)
# Unpack everything
X_train = artifacts["X_train"]
X_val = artifacts["X_val"]
X_test = artifacts["X_test"]
y_train = artifacts["y_train"]
y_val = artifacts["y_val"]
y_test = artifacts["y_test"]
y_class_train = artifacts["y_class_train"]
y_class_val = artifacts["y_class_val"]
y_class_test = artifacts["y_class_test"]
label_mapping = artifacts["label_mapping"]
pattern_to_id = artifacts["pattern_to_id"]
id_to_pattern = artifacts["id_to_pattern"]
class_weights_dict = artifacts["class_weights_dict"]
pos_weights_tensor = artifacts["pos_weights_tensor"]
history_cnn = artifacts["history_cnn"]
history_tl = artifacts["history_tl"]
hist_p2_cnn_a = artifacts["hist_p2_cnn_a"]
hist_p2_cnn_b = artifacts["hist_p2_cnn_b"]
hist_p2_tl_a = artifacts["hist_p2_tl_a"]
hist_p2_tl_b = artifacts["hist_p2_tl_b"]
BinaryFocalLoss = artifacts["BinaryFocalLoss"]
focal_loss = artifacts["focal_loss"]
THRESHOLD = artifacts["THRESHOLD"]
NUM_CLASSES = artifacts["NUM_CLASSES"]
BATCH_SIZE = artifacts["BATCH_SIZE"]
EPOCHS = artifacts["EPOCHS"]
TARGET_SIZE = artifacts["TARGET_SIZE"]
AUTOTUNE = artifacts["AUTOTUNE"]
print("✓ All artifacts loaded")
# Verify everything loaded correctly
print("\n" + "=" * 60)
print("Verification:")
print("=" * 60)
print(f"X_train shape: {X_train.shape}")
print(f"y_class_test shape: {y_class_test.shape}")
print(f"NUM_CLASSES: {NUM_CLASSES}")
print(f"Models loaded: {model_cnn.name}, {model_tl.name}, {model_p2_cnn.name}, {model_p2_tl.name}")
# Quick prediction test
test_ds_p2 = build_dataset(X_test, y_class_test)
test_batch = next(iter(test_ds_p2))
pred_cnn_p2 = model_p2_cnn.predict(test_batch[0], verbose=0)
print(f"✓ Model prediction successful (shape: {pred_cnn_p2.shape})")
print("\nAll artifacts loaded successfully! ✓")